Parallelization of Software Mpeg Compression
Fang Wang
![]()
![]()
What is Mpeg?
Mpeg(Motion Picture Expert Group)-1 is an ISO/IEC (International
Organization for Standardization/ International Electrotechnical
Commission) standard for medium quality and medium bit rate video and
audio compression.
In video streams, adjacent frames tend to be very similar. In short, Mpeg compression makes use of this temporal reduncy of the data and allows video to be compressed by the ratios in the range of 50:1 to 100:1. There are 3 kinds of frames in the video stream, each of which is compressed differently:
An I-frame is encoded as a single image, with no reference to any past or future frames. The encoding scheme used is similar to JPEG compression.
A P-frame is encoded relative to the past reference frame. A reference frame is a P- or an I-frame. The past reference frame is the closest preceding reference frame.
A B-frame is encoded relative to the past reference frame, the future reference frame, or both frames. The future reference frame is the closest following reference frame (I or P). The encoding for B-frames is similar to P-frames, except that motion vectors may refer to areas in the future reference frames.
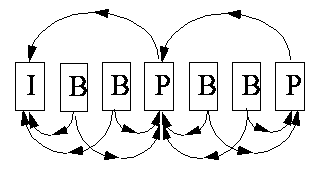
The figure above shows the inter-frame dependencies in a stream, if an
IBBPBBP compression pattern has been specified. A compression pattern is
a parameter that can be controlled by the user.
The purpose of this project is to achieve a decent
frame rate (~10) using software Mpeg compression.
Currently, running on a 18 processor workstation, and using up to 10 processors for parallel compression, a frame rate as high as 8.34 fps has been achieved with a resoluation of 200x200. Extensive test on the program is needed to determine the overhead of multi-processes management, and optimize the performance of compression. My work is an extension of the previous work done on parallel mpeg compression at UC Berkeley.
The major functionalities include:
An Overview of the system :
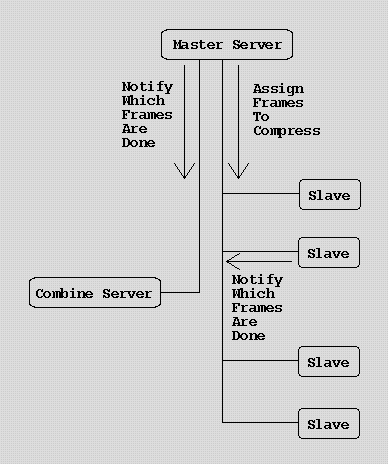
Figure above : an overview of the system, without the Decode Server.
Coarse Level Parallelism :
Parallel Mpeg compression is achieved here by having multiple processors perform compression on different "chunks" of input frames, therefore a "coarse level" parallel compression. First of all, the user need to supply a number of extra parameters for the system to run in parallel:
# number of frames to do initially to gauge speed of machine
PARALLEL_TEST_FRAMES 10
# number of seconds per chunk thereafter
PARALLEL_TIME_CHUNKS 20
# first processor number to be used
# this is to be used by the master, output and decode server
PROCESSOR_FIRST 0
# total number of processors to be used
PROCESSOR_USE 7
# number of slave processes actually doing the compression
PROCESS_SLAVES 6
The key to "good" parallelization is how to synchronize the slave processes so that no slave process is kept waiting for assignment from the master of the frames to compress, or to notify the master of the frames done, and that output server is not waiting for a "slower" slave process for the output frames to generate the mpeg file.
The first part of the question, depends on how fast the master
handles requests from the slave processes. A number of things have to happen
when the master accepts a request from a slave process:
A special case has to be taken care of when the end of the stream is reached. A contention is possible here if all slaves finish compressing of assigned frames and try to connect to master at the same time. This wait situation can be avoided if a "concurrent" master server is implemented, details of which will be covered in "Currently Under Work" section.
To avoid the second kind of wait situation, the user has to supply a parameter "PARALLEL_TIME_CHUNKS", and the master server is keeping track of the frame rate of all individual slave processes. When a slave is done compression of assigned frames, and asking for more frames, the master compute the number of frames to assign to this slave by:
And initially each slave process is given PARALLEL_TEST_FRAMES of frames, a parameter also set by the user.
Can one achieve linear speed-up using multiple processors? The answer lies in whether combined frame rate from all processor outweighs the overhead of processe communication and management. Look at the example below, 3 slaves processes on 3 processors were used for compression, with master and output servers running on a separate processor. The individual frame rate of the 3 processes were 1.25, 1.21, and 1.25 respectively. Therefore an optimal frame rate of 3.71 can be achieved. But in actuality, the overall frame rate was 3.27. This is partly due to the fact that the output server is still running to combine all the output frames to an mpeg file even after all slave processes have finished.
MPEG ENCODER STATS (1.5b)
------------------------
TIME STARTED: Tue Apr 29 12:24:35 1997
MACHINE: zbox
OUTPUT: ../test/output.mpg
PATTERN: ibbpbbpbbp
GOP_SIZE: 10
SLICES PER FRAME: 1
RANGE: +/-10
PIXEL SEARCH: HALF
PSEARCH: LOGARITHMIC
BSEARCH: CROSS2
QSCALE: 8 10 25
REFERENCE FRAME: ORIGINAL
PARALLEL SUMMARY
----------------
START UP TIME: 0 seconds
SHUT DOWN TIME: 3 seconds
MACHINE Frames Seconds Frames Per Second Self Time
-------------- ------ ------- ----------------- ---------
Slave #0 85 68 1.250000 240
Slave #1 108 89 1.213483 248
Slave #2 108 86 1.255814 239
-------------- ------ ------- ----------------- ---------
OPTIMAL 80 3.719297
ACTUAL 92 3.271739
Some Results :
| Number of Slaves | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| Optimal Frame Rate | -- | 2.39 | 3.72 | 4.78 | 5.01 | 4.79 | 4.91 | 5.27 | 5.77 | 8.22 |
| Actual Frame Rate | 1.49 | 2.35 | 3.27 | 4.55 | 4.93 | 4.63 | 4.74 | 4.76 | 5.03 | 6.46 |
We see a good speed-up from 1 processor to 5 processors, from the runs above. However, adding more processors after 5 has little effect on the speed. This is, I think, due to the socket protocals used for communication here. Since a connection-oriented listening socket (server) can have at most 5 connection requests queued, 5 processes including the output server, therefore, can queue requests for sending messages to the server at one time.
Currently Under Work :
1. The use of the Decode Server has not been tested throughly, which is necessary if decoded frames are used for reference.
2. Can we have the slave processes notify the output server directly of the frames done, instead of going through the master? This will go against the principle that a master process is controlling the synchronization of all processes, but it will get rid of some unnecessary message passing.
3. One can also try using "concurrent" connection-oriented listening sockets for the servers. That is, everytime a server socket accepts a request for connection, it will first fork a child and have the child handle the request, and the parent will continue "listening" for more request. This should enable the server to handle the requests from slave processes in a concurrent fashion.
This means, however, multiple processes will update the information such as which frames are done, etc., which has to be kept track in shared memory. Thus a little more overhead is involved if a concurrent master server is used.
Preliminary results show considerable improvement over the old scheme.
| Number of Slaves | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| Optimal Frame Rate | 7.16 | 8.75 | 9.40 | 10.27 | 11.30 | 11.36 | 11.68 |
| Actual Frame Rate | 6.67 | 8.00 | 8.07 | 8.20 | 8.01 | 8.34 | 8.27 |
Things to Keep in Mind in concurrent programming:
1. If a process is terminated, any child processes it has created should be terminated first.
2. If a process is terminated, any system resources it has allocated should be released first.
3. Same things should happen even if the process is killed abnormaly, e.g., when ctrl-c is pressed.
![]() Link to Berkeyly's
Mpeg project
Link to Berkeyly's
Mpeg project