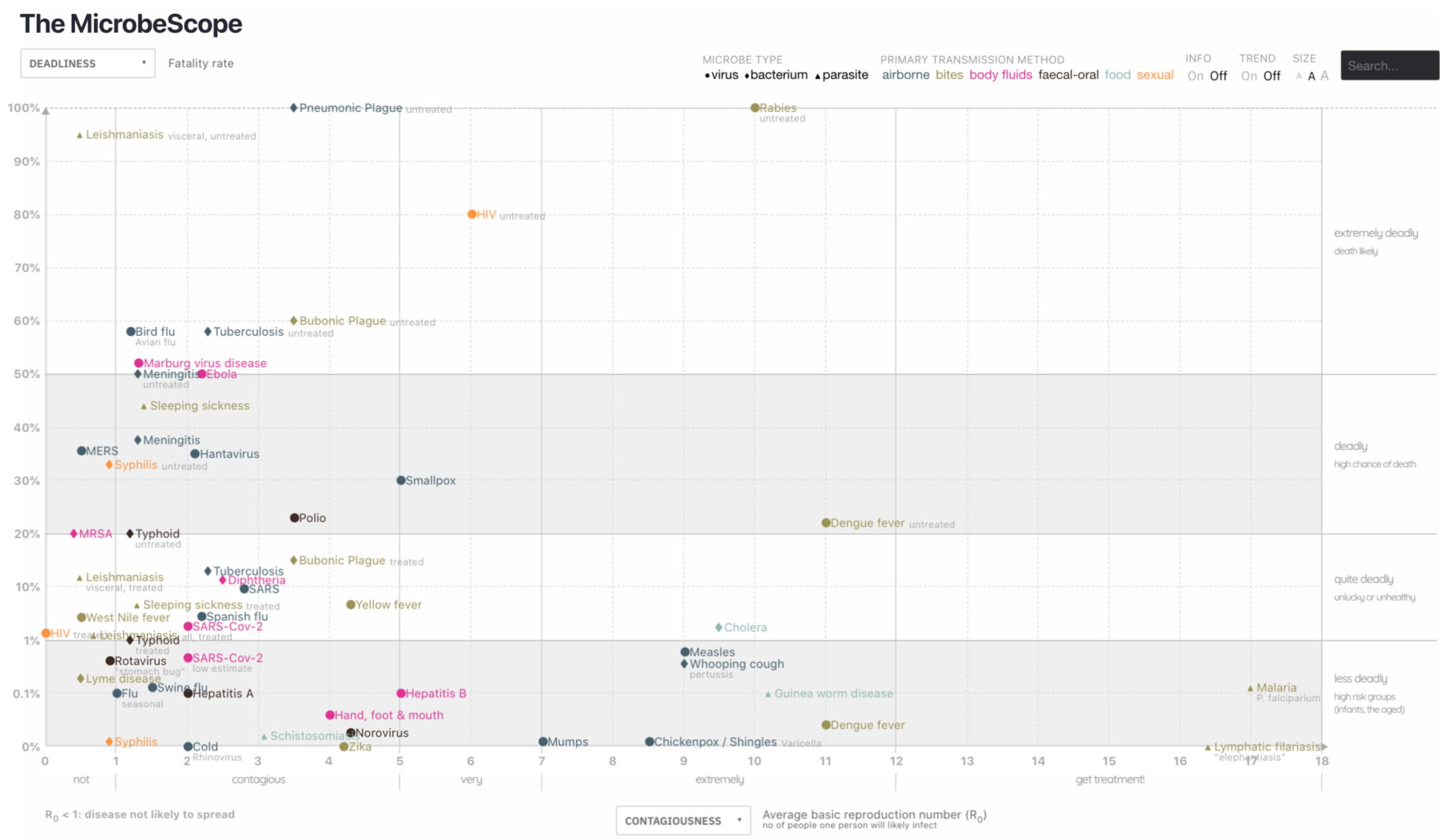
Back in Week 1 we took a
look at the classic John Snow Cholera visualization. How does
cholera compare to other infectious diseases. This modern
scatter plot gives us some context, relating contagiousness to
deadliness, and color coding by primary method of transmission.
And
a modern visualization comparing different infectious diseases
as a basic labelled scatterplot but with the interactive
features we expect today
https://www.informationisbeautiful.net/visualizations/the-microbescope-infectious-diseases-in-context/
tagCrowd - https://tagcrowd.com/








There are variations on this where the words
are at all different angles, and in random order, and in random colors such as https://www.wordclouds.com/
Keeping the text horizontal makes it more readable, and
picking an order like alphabetical order makes it easier to
search for words across the different sets.
In these cases the visualizations dealt with simple words rather than common phrases, which may be more useful, but require a bit more intelligence to process.
|
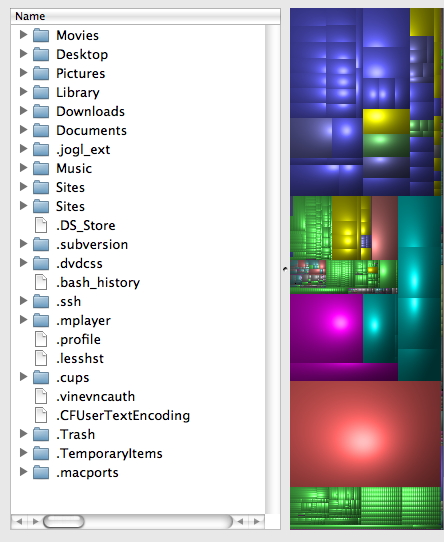
DiskInventoryX or
SupaView on the Mac and WinDirStat on Windows
can be used to see relative file sizes on disk using
treemaps, flattening out the directory hierarchies but
keeping the hierarchies visible as nested boxes, and
color-coding by file type. It would be better to avoid
the 3D highlighting affects - http://www.cs.umd.edu/hcil/treemap-history/index.shtml
Once the treemap is drawn the user can click on a large (or small) box and see it identified in the hierarchy, or click on part of the hierarchy and see its area. Its easy to explore the larger files, but much harder to explore the smallest ones, unless one restricts the map to only a subset of the hierarchy. This makes treemaps a very useful tool if the size of the box is directly related to its importance - and in the case of the question 'what happened to all my disc space?' that is very often true. Here 2D squares are sized appropriately, as opposed to some of the designs we looked at last week, so they do give the user a good sense of how much space various types of files take up, from many small emails or music files to large virtual machines or movies. Human beings are pretty good at understanding the relative sizes of squares and estimating how many of this square can fit into that one, where we are less good at doing that with triangles, or circles, or barrels, or spheres. |
 |
|
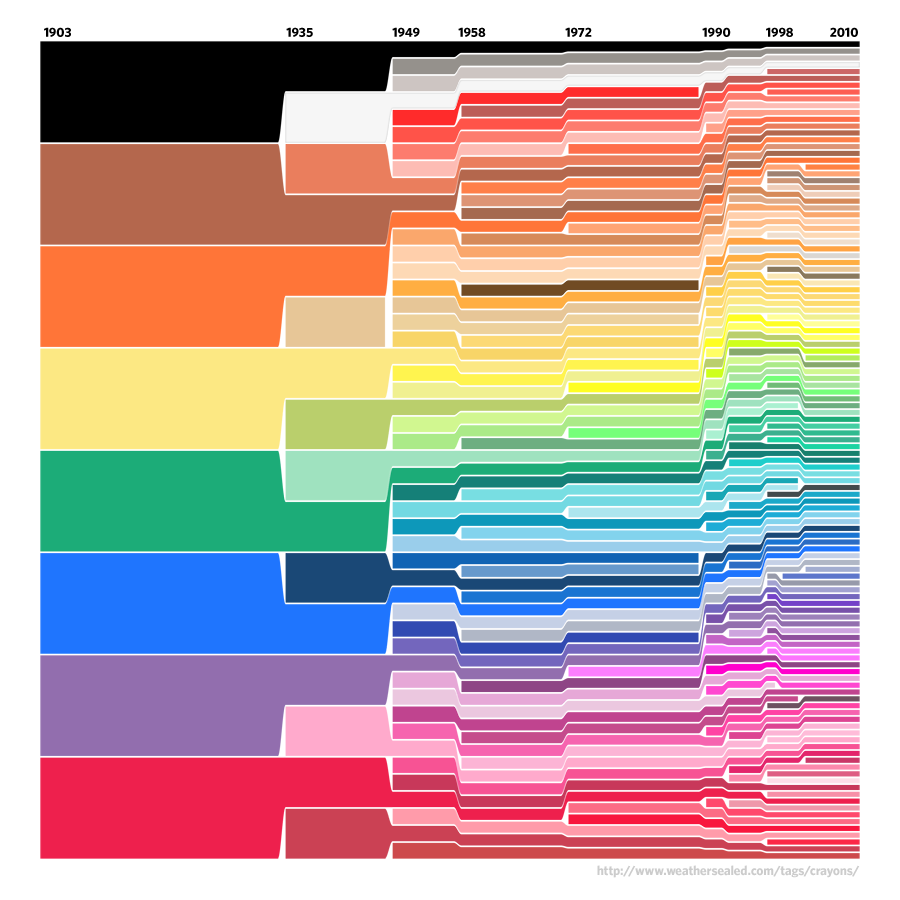
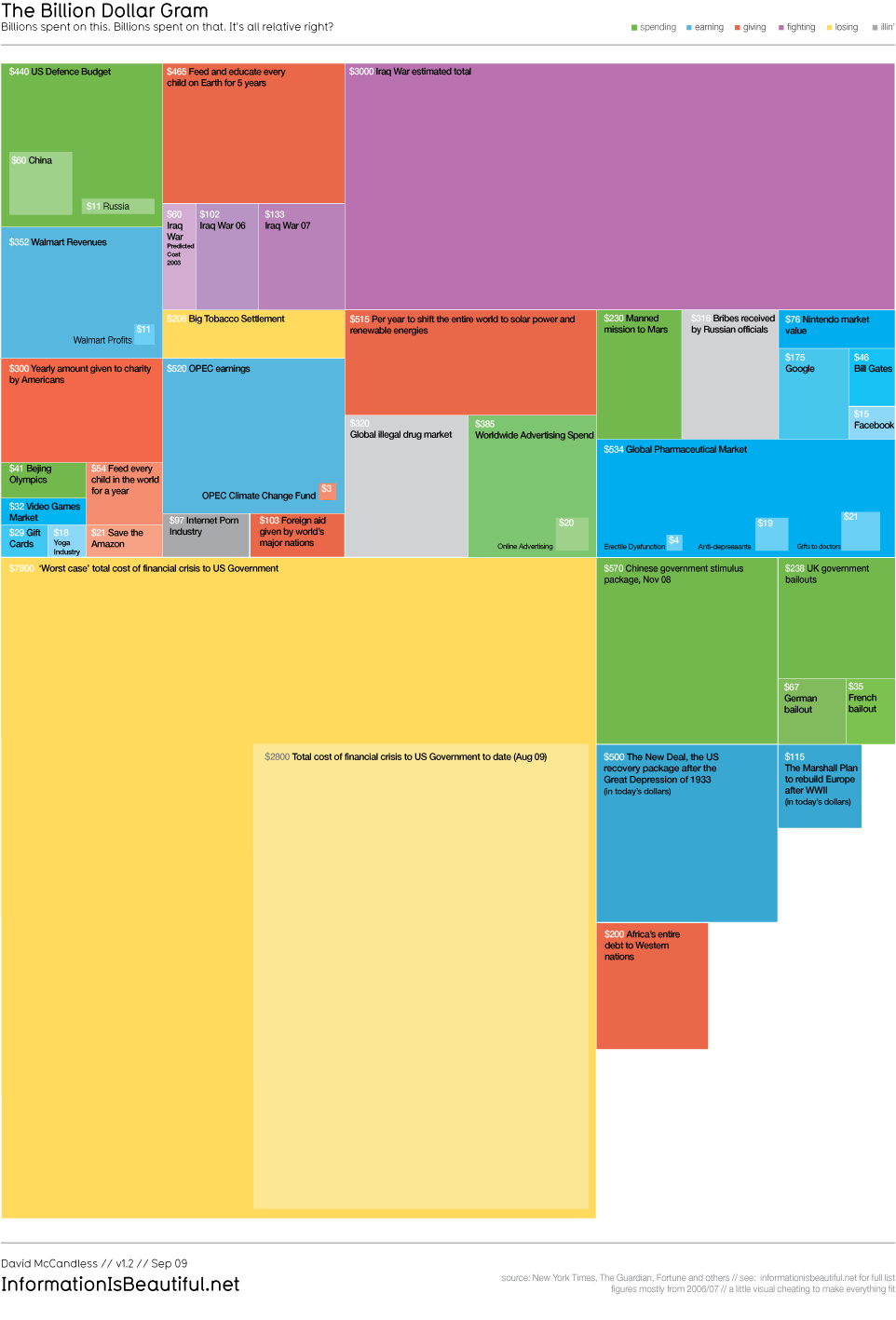
A similar styled chart looking at relative
amounts of dollars spent (or lost) on various things is
The Billion Dollar Gram allows people to compare things
that they may not normally think about comparing -
depending on what a user is familiar with. Unlike the
space on a hard drive there is no 'total' number here,
just a variety of costs being compared by their areas.
https://www.informationisbeautiful.net/visualizations/the-billion-dollar-gram/ |
 |
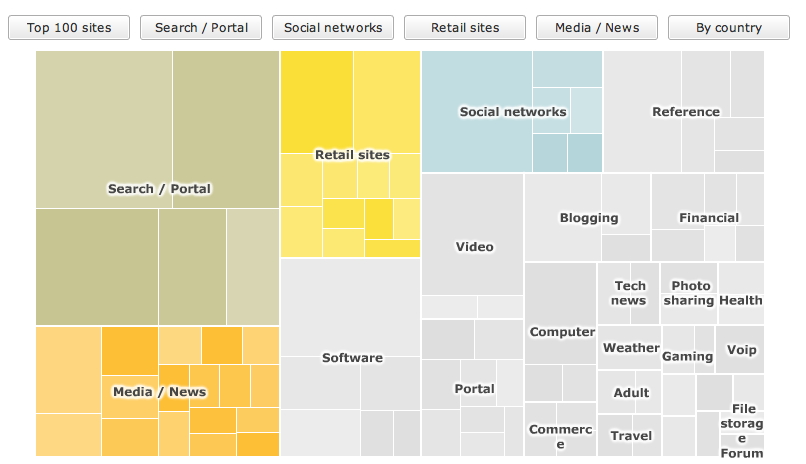 |
The BBC
used to have a nice flash-based treemap of the top 100
sites on the internet - http://news.bbc.co.uk/2/hi/technology/8562801.stm |
 |
Newsmap (flash-based) previously showed the news of the moment in a similar style where more important news items are shown larger, and all are color coded by topic - http://newsmap.jp |
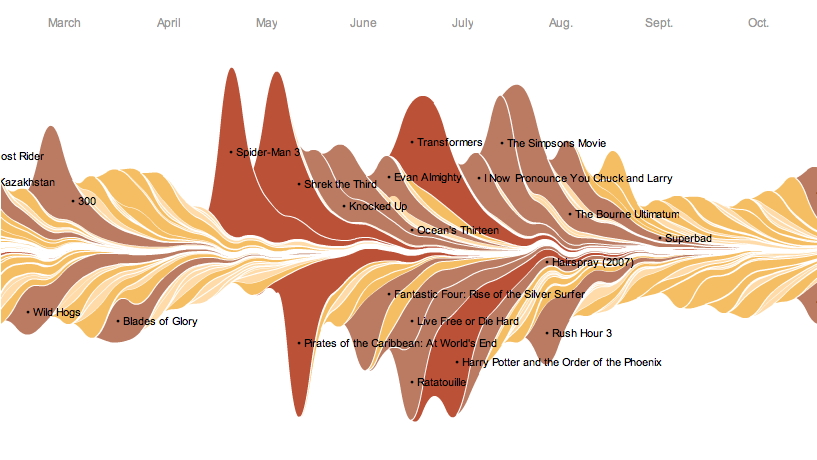
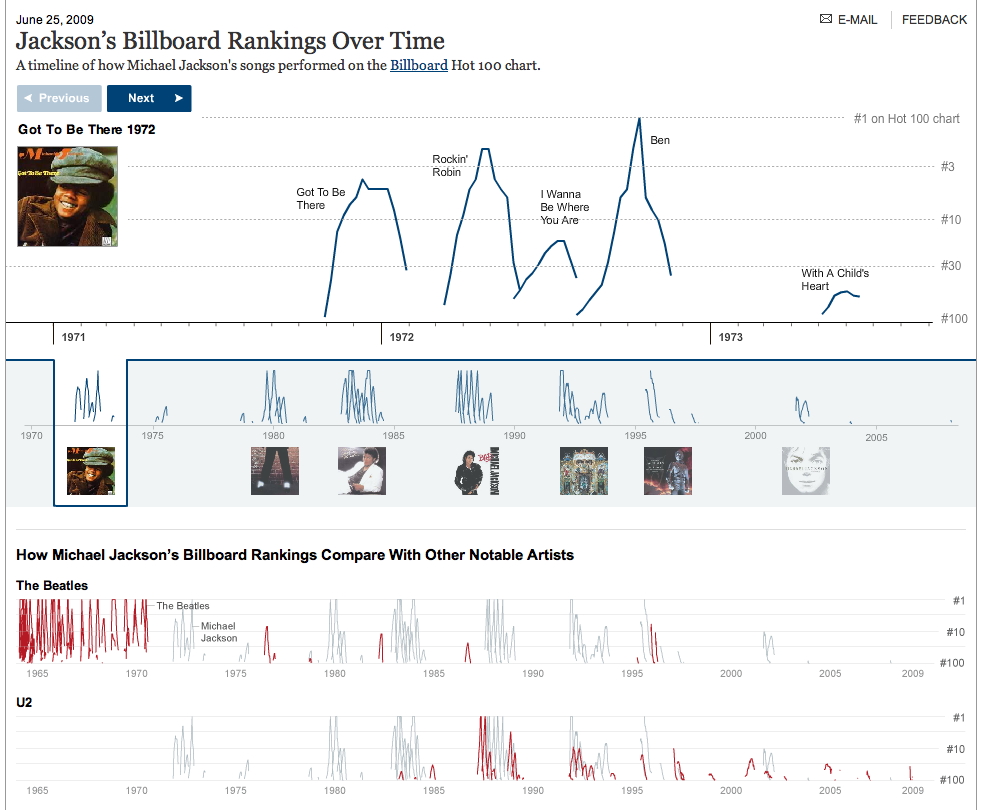 |
NY times
(flash-based) Billboard Rankings page was a nice way to
compare different singers over the decades in terms of how
their songs were charting in relation to each other http://www.nytimes.com/interactive/2009/06/25/arts/0625-jackson-graphic.html?hp |
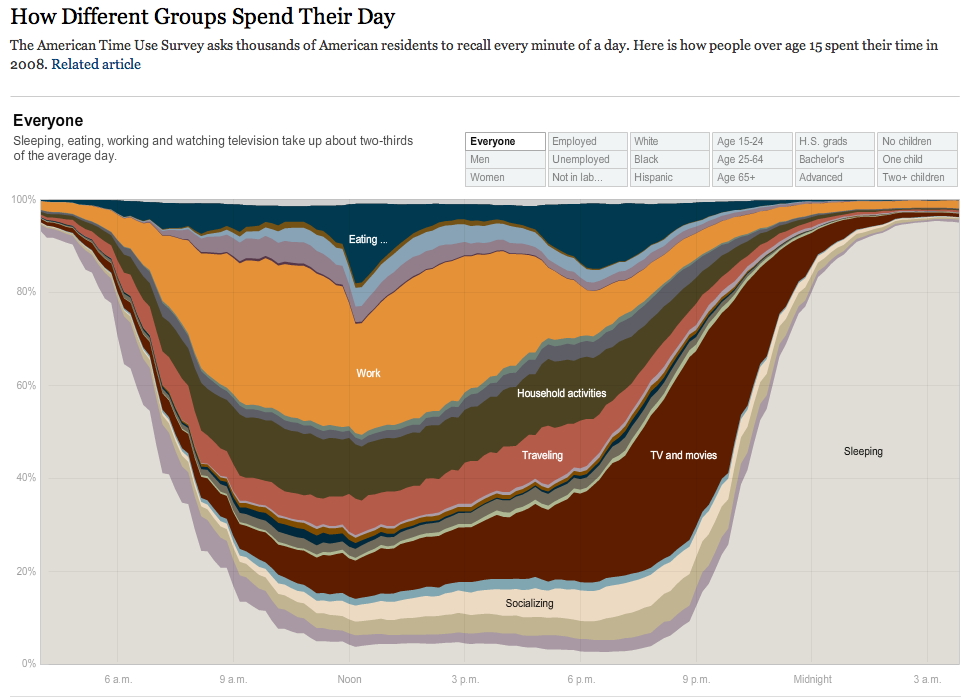 |
There is
another version of this where all of the different flows
at up to 100% all of the time. For example What are people
doing in Japan (java-based)? http://www.xoxosoma.com/tokyo-tuesday/ and a similar one showing how people in the US spend their days (flash-based): http://www.nytimes.com/interactive/2009/07/31/business/20080801-metrics-graphic.html?hp and a version that breaks this same data out into separate graphs: http://projects.flowingdata.com/timeuse/ |
| name
voyager allows a user to investigate how common different
names have been over the last 150 years -
http://www.babynamewizard.com/voyager with more data at: http://www.bewitched.com/namevoyager.html and background at: https://namerology.com/2021/12/02/looking-back-babynamewizard-com-2004-2021/ |
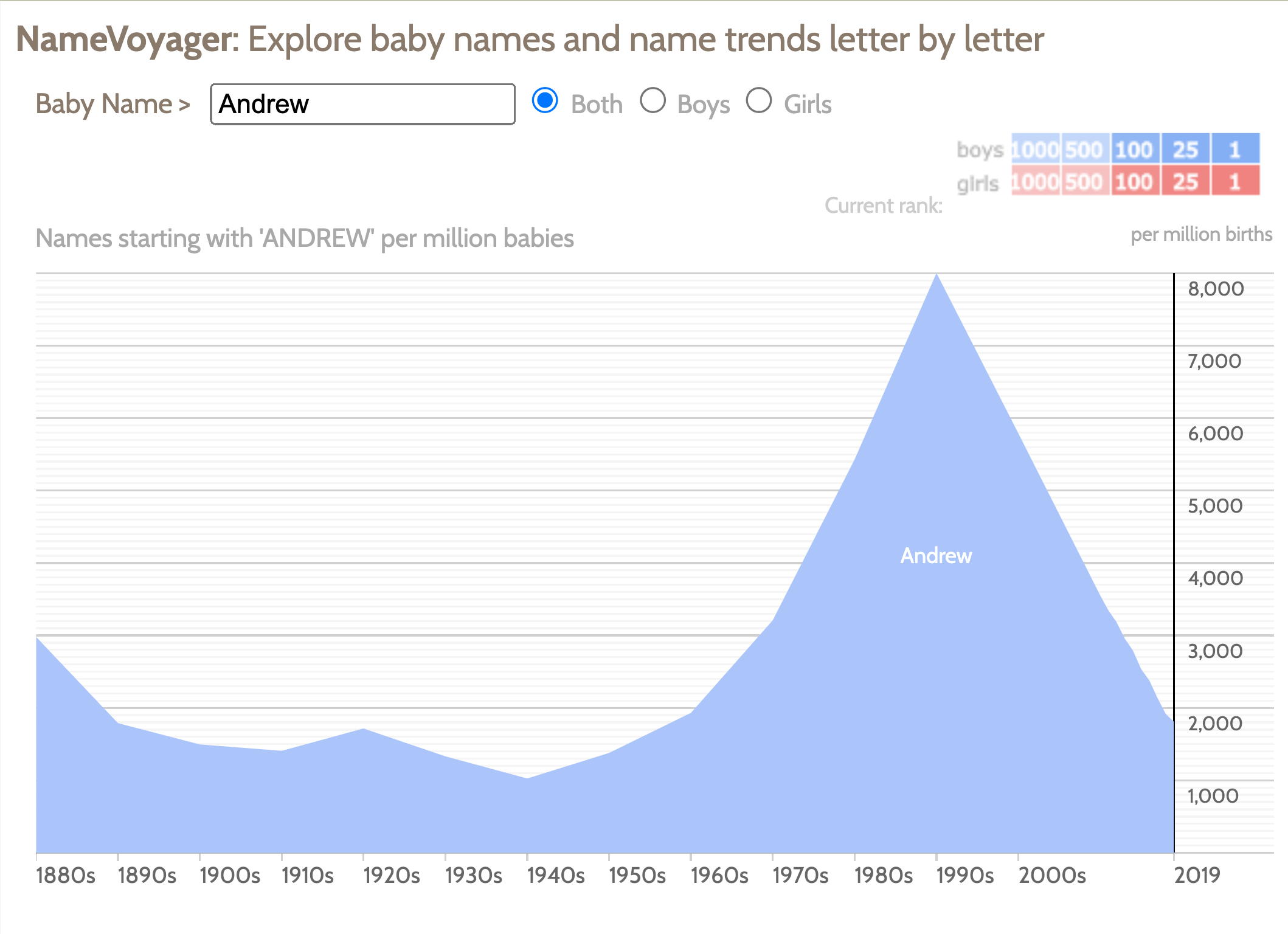 |
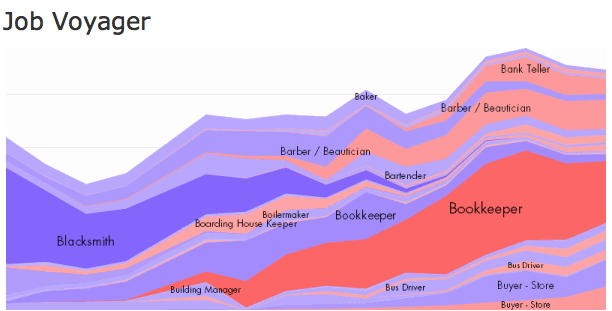 |
job
voyager (flash-based) used to exist at
http://flare.prefuse.org/apps/index looking at how common different jobs have been over the past 150 years but there is a not-quite-as-good version available at: https://vega.github.io/vega/examples/job-voyager/ |
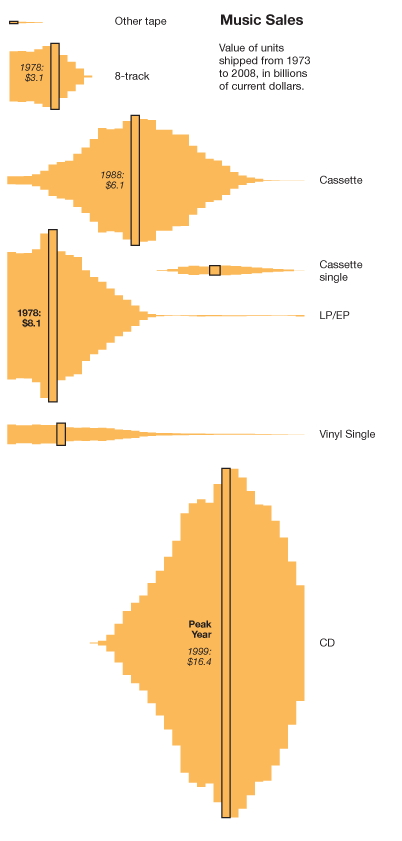
and another nice one related to the the popularity of different media for selling music - which were popular at the same time, which began replacing another, which were never popular at all - http://www.nytimes.com/imagepages/2009/08/01/opinion/01blow.ready.html |
 |
Two
visualizations of global average temperatures - on the left a
more traditional plot, and on the right Ed Hawkins' Warming
Stripes for 1850 to 2018, using a diverging color scheme (blue
for below average, white for average, red for above average) to
color the lines. While the traditional plot is good for people
who understand plots and charts, the warming stripes may be a
better way to show the same data, without distorting it, to a
lay audience, simultaneously showing the overall trend and the
complexity in the data while being suitable for a lapel pin or a
T-shirt or an on-line account photo. Visualizations don't need
to be limited to paper or screens.
Adding
a title and x-axis labels and a legend would turn the Warming
Stripes into a more serious visualization, but the data
visualization itself is solid with a good choice of colors and
long lines that make the slight differences in some of the
colors visible
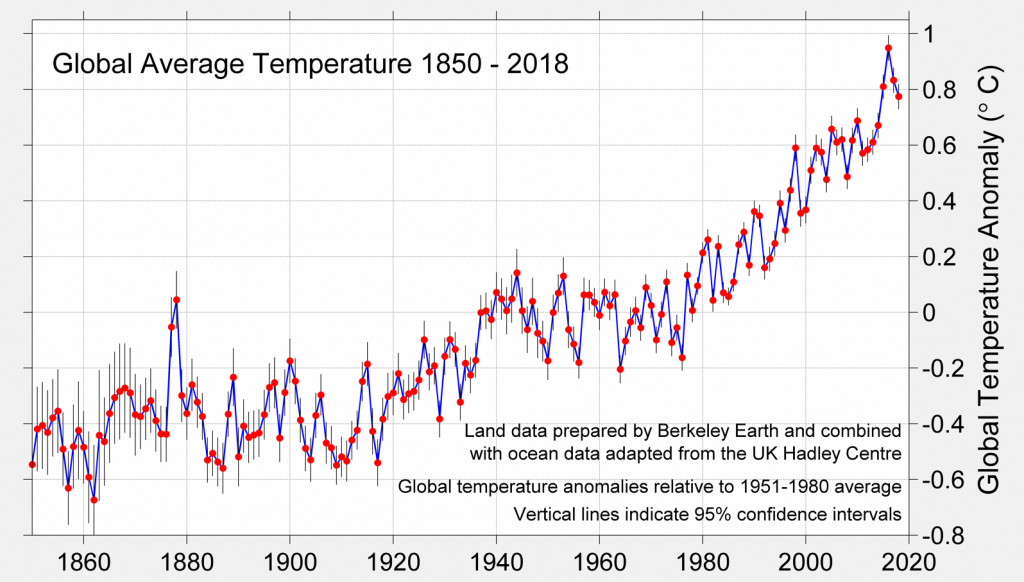
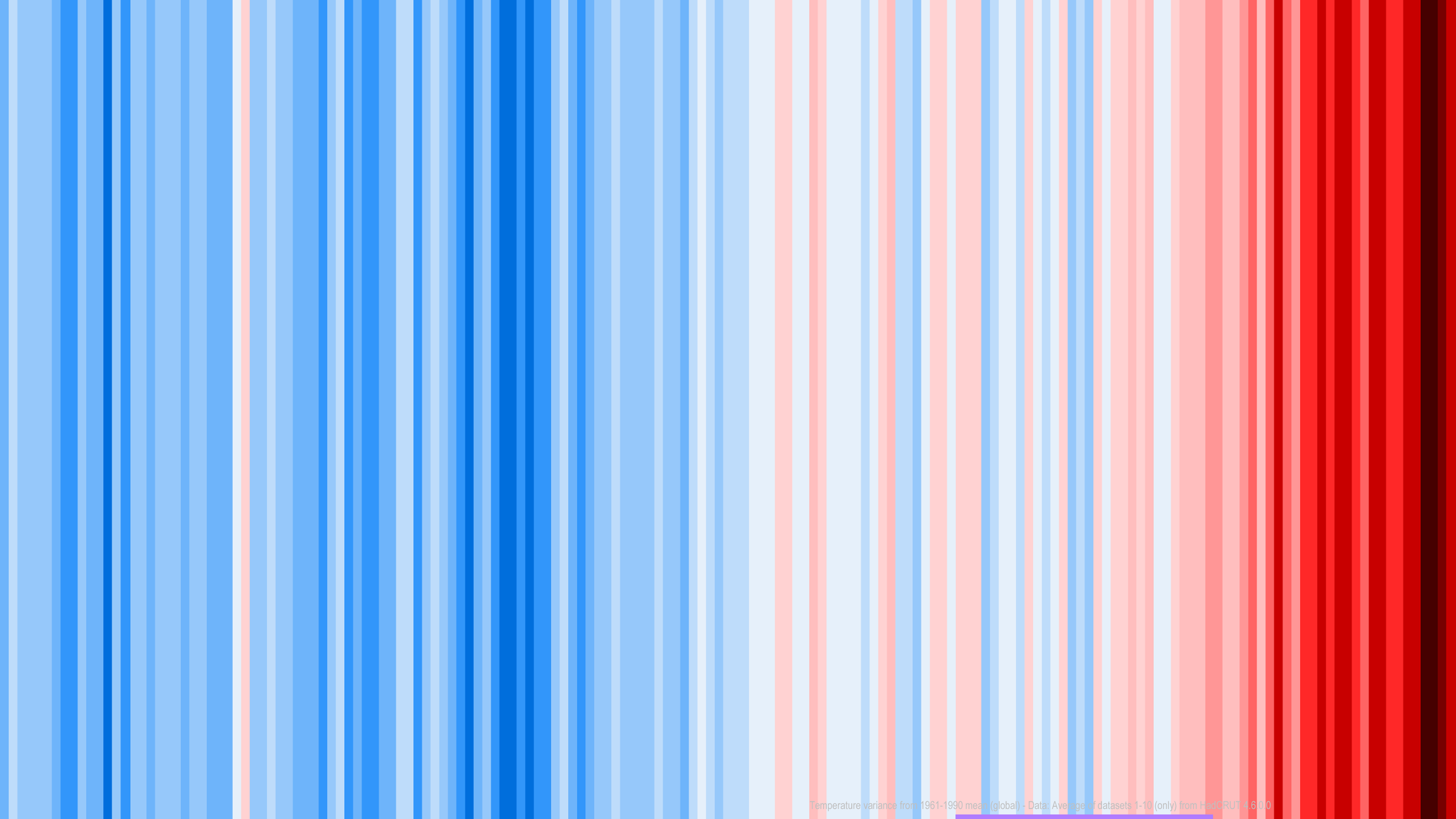
(images from http://berkeleyearth.org/2018-temperatures/ and Wikipedia - https://en.wikipedia.org/wiki/Warming_stripes)
(data from http://berkeleyearth.lbl.gov/auto/Global/Land_and_Ocean_summary.txt)
similarly this animation
below is good for getting a visceral feel for the data it
represents
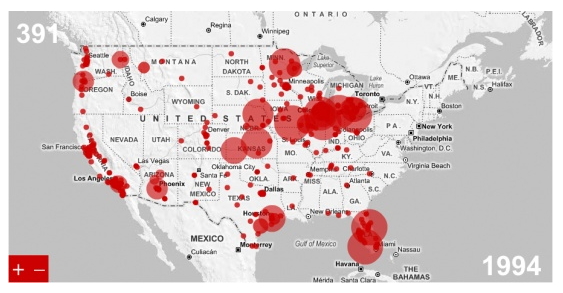 |
(flash-based)
growth of target (earthquake data is often visualized the
same way) - http://projects.flowingdata.com/target/ There is a similar one for Walmart that is still viewable as a non-interactive animation - https://flowingdata.com/2010/04/07/watching-the-growth-of-walmart-now-with-100-more-sams-club/ we
will talk more about animation later in the course. This
one is nice and simple - just red circles (appropriate
for Target) or blue circles for Walmart on a very basic
map of the US with state boundaries and some major
geographic features. This one is very good for getting a
visceral feel for the rate of expansion and the
locations, but for more numeric comparisons it would be
good to augment this with a graph showing how many
stores open per year across the country or in different
regions
|
| Below is
a interesting way of visualizing the distance to nearby
stats from http://strangemaps.wordpress.com/ in terms of
what Earth programs they are just receiving (now a few
years out of date) but still putting a set of distances
that are hard to understand into a temporal context that
may be easier to understand: and a variant with radio - http://lightyear.fm |
 |
|
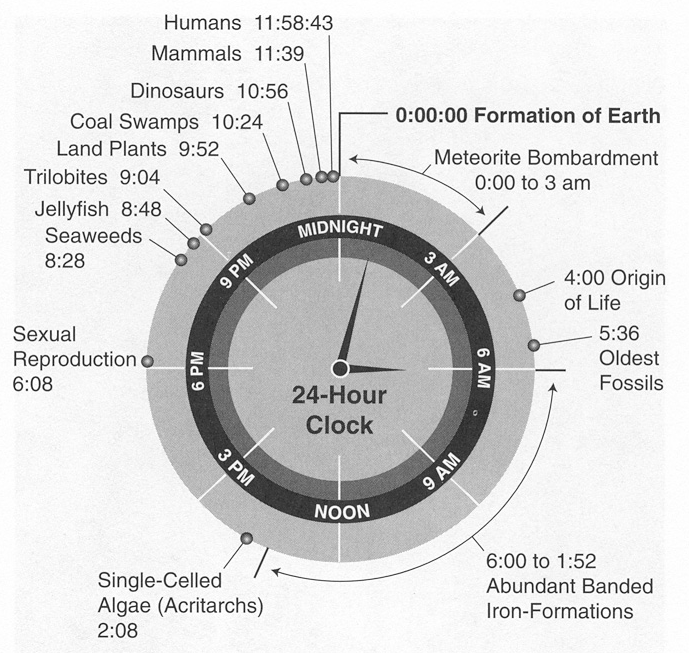
|
and a little closer to home, the history of Earth reduced to 24 hours from http://www.geology.wisc.edu converting time scales that we have very little sense of into a time scale that we are more used to. |
and a shorter
4 minute excerpt:
http://www.youtube.com/watch?v=Bg3pfUqdLp4
and you can
see the history of the maps at:
https://londonist.com/2016/05/the-history-of-the-tube-map
Compare this
map of the CTA
https://www.transitchicago.com/assets/1/6/ctamap_Lsystem.png
to these maps of the CTA
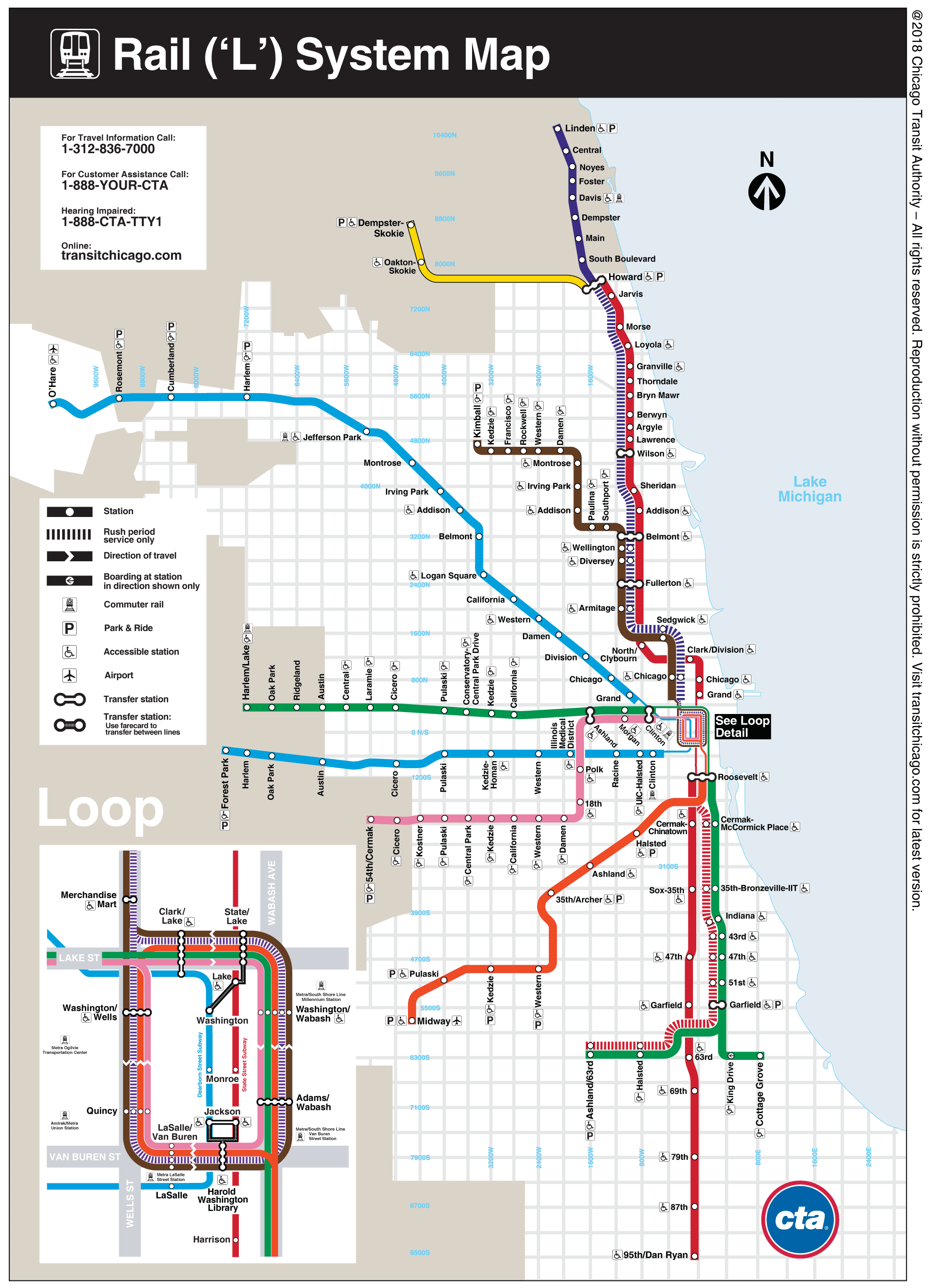 |
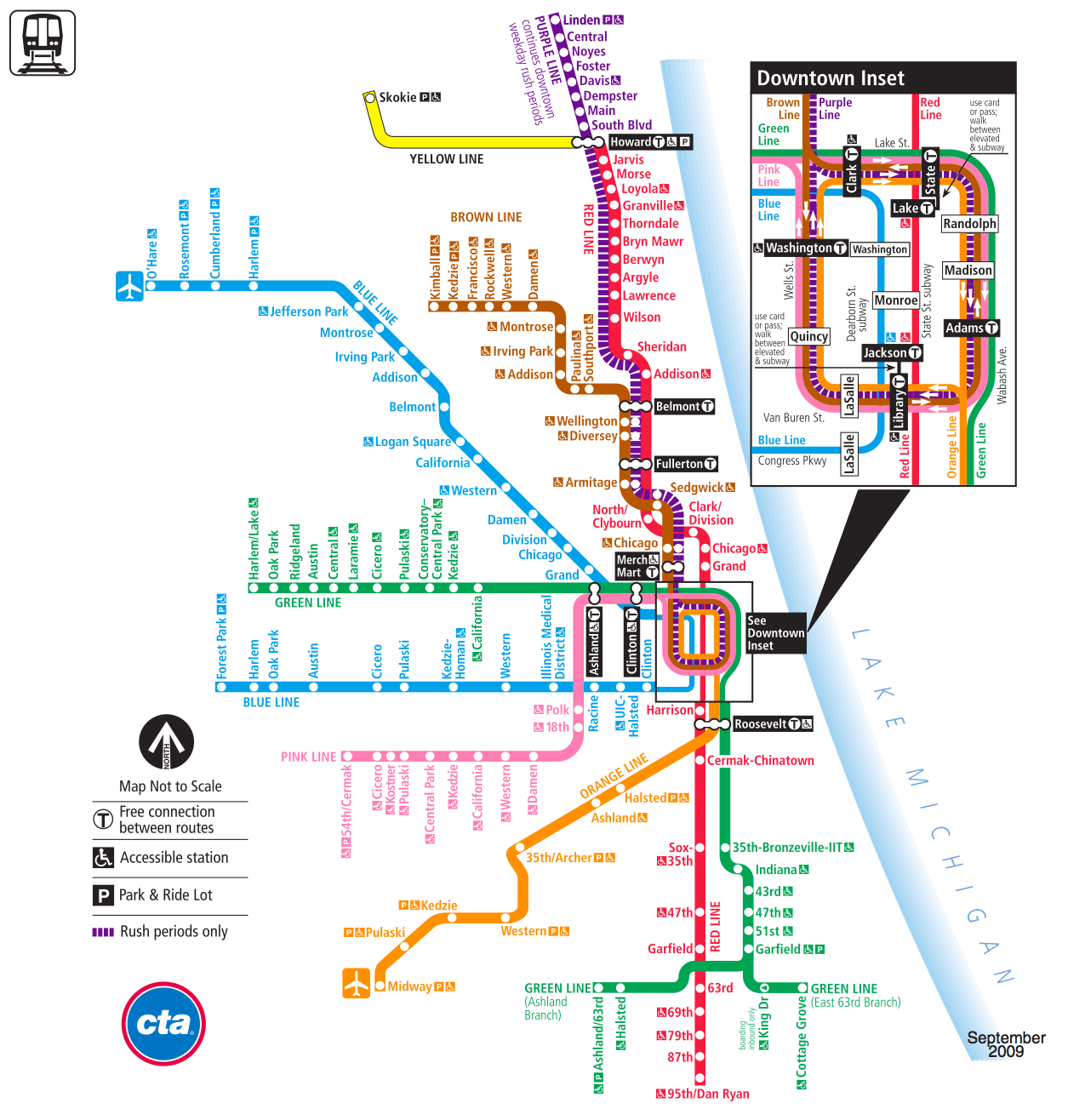 |
Line Map
For more
information on the evolution of the CTA lines and colors there is
https://interactive.wttw.com/chicago-by-l/sidetracks/how-cta-map-got-its-colors
Harry Beck's design is still evident in the live NY subway
visualization at
https://map.mta.info/
Much of what was shown above had the data already filtered and the visualizations were created to illuminate specific trends in the data. But if you are starting to look at a dataset with a bunch of different dimensions how do you get a handle on it. Statistics can be one place to start, but it can also help to try and get an overview of the data in all the various dimensions at once,
A couple ways to do this are Parallel Coordinates and Scatterplot Matrices (sploms)
Lets take a look at the
classic Motor Trend Car dataset which has 406 observations on
the following 8 variables / dimensions:
Some of these are continuous
variables (MPG, displacement, horsepower, weight, acceleration
time)
Some are discrete variables (# cylinders, model year)
And one is categorical with no natural ordering (origin)
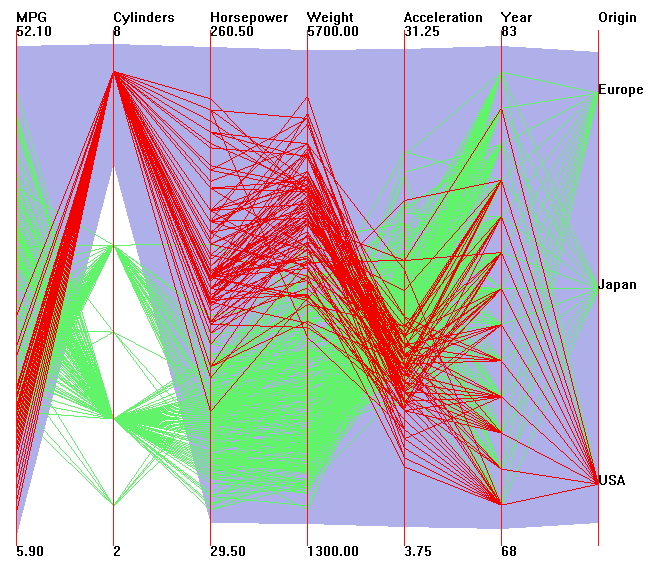
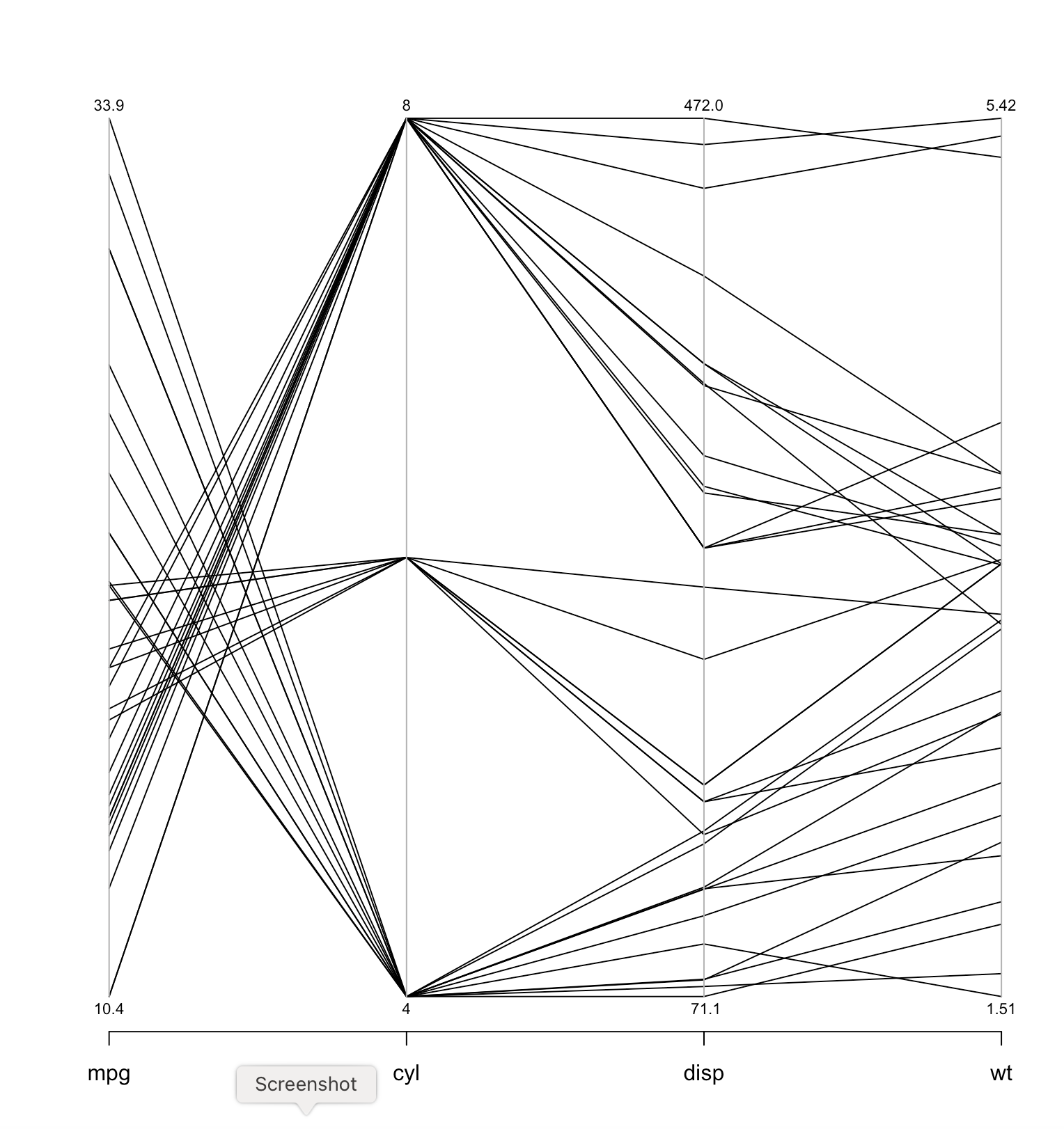
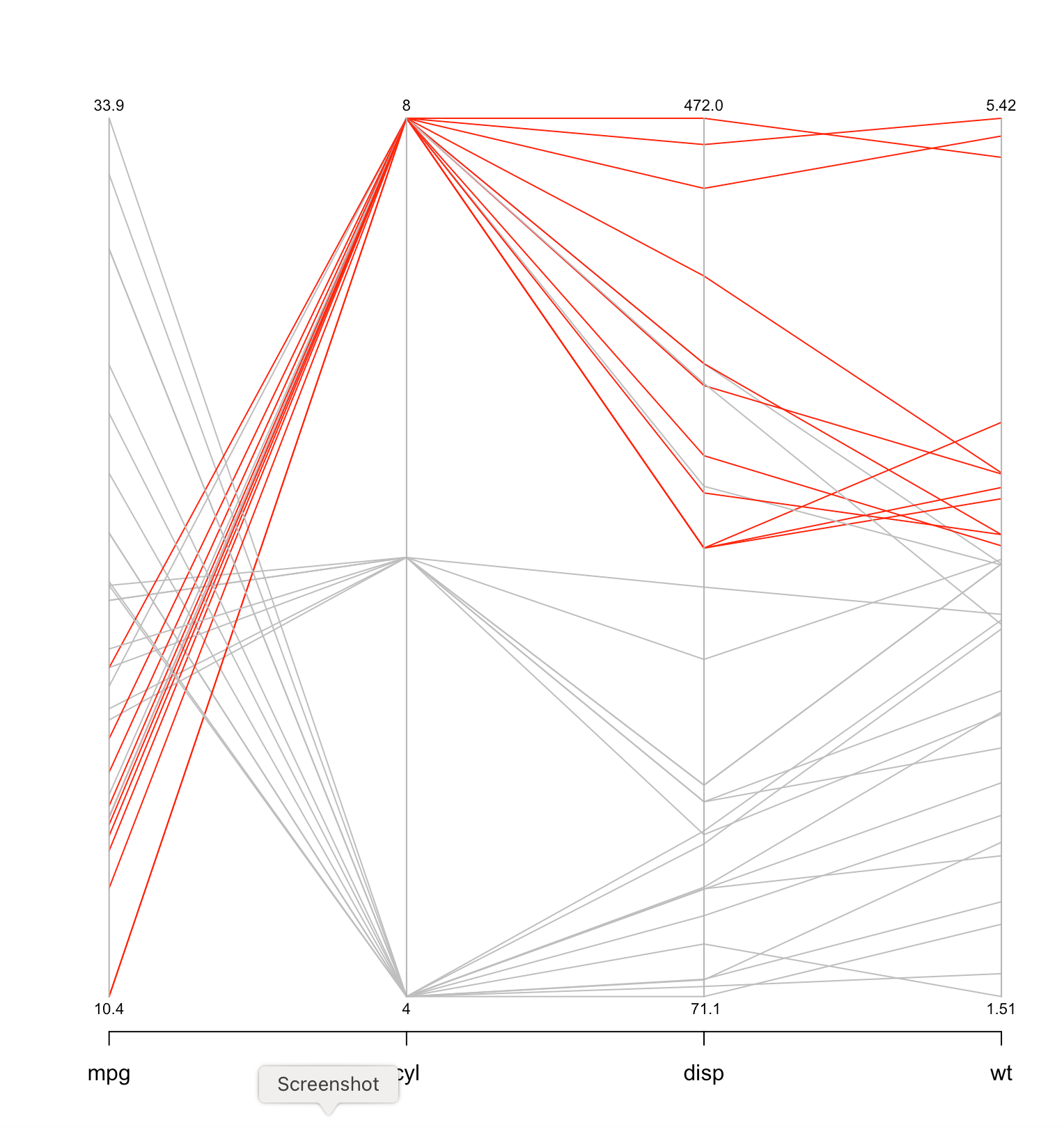
With
Parallel Coordinates each variable (e.g. MPG, Cylinders) becomes
a column (e.g. low MPG at the bottom of the column to high MPG
at the top of the column) and a particular car becomes a
segmented line crossing all of those columns at the appropriate
point in each column.
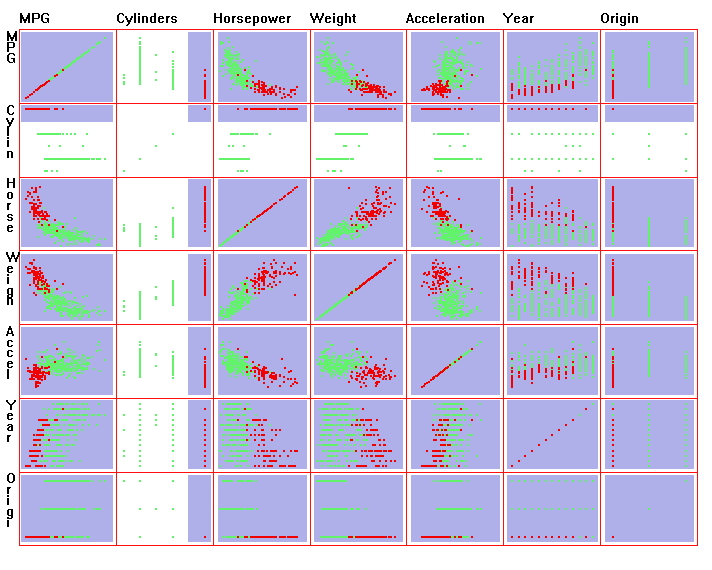
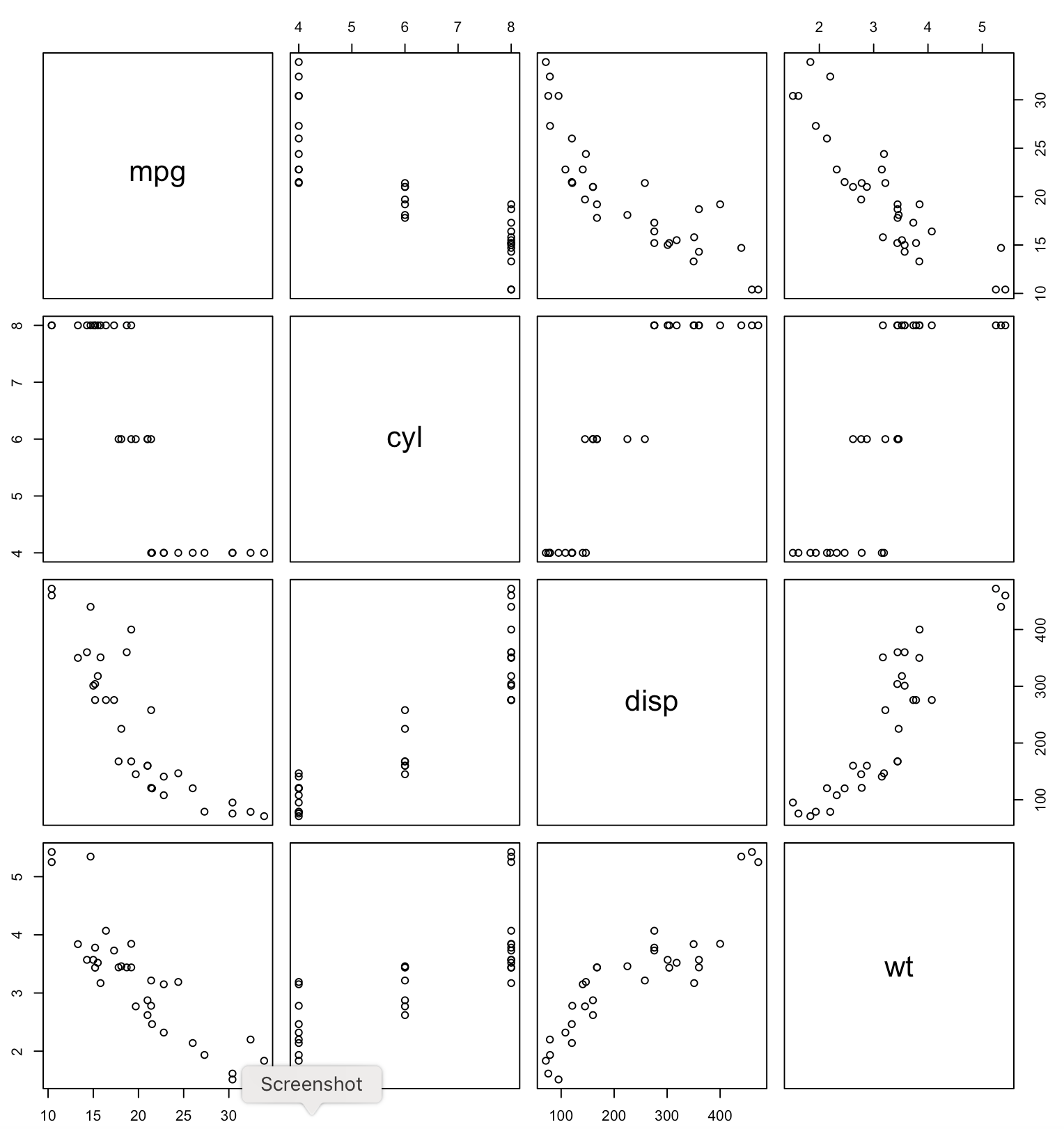
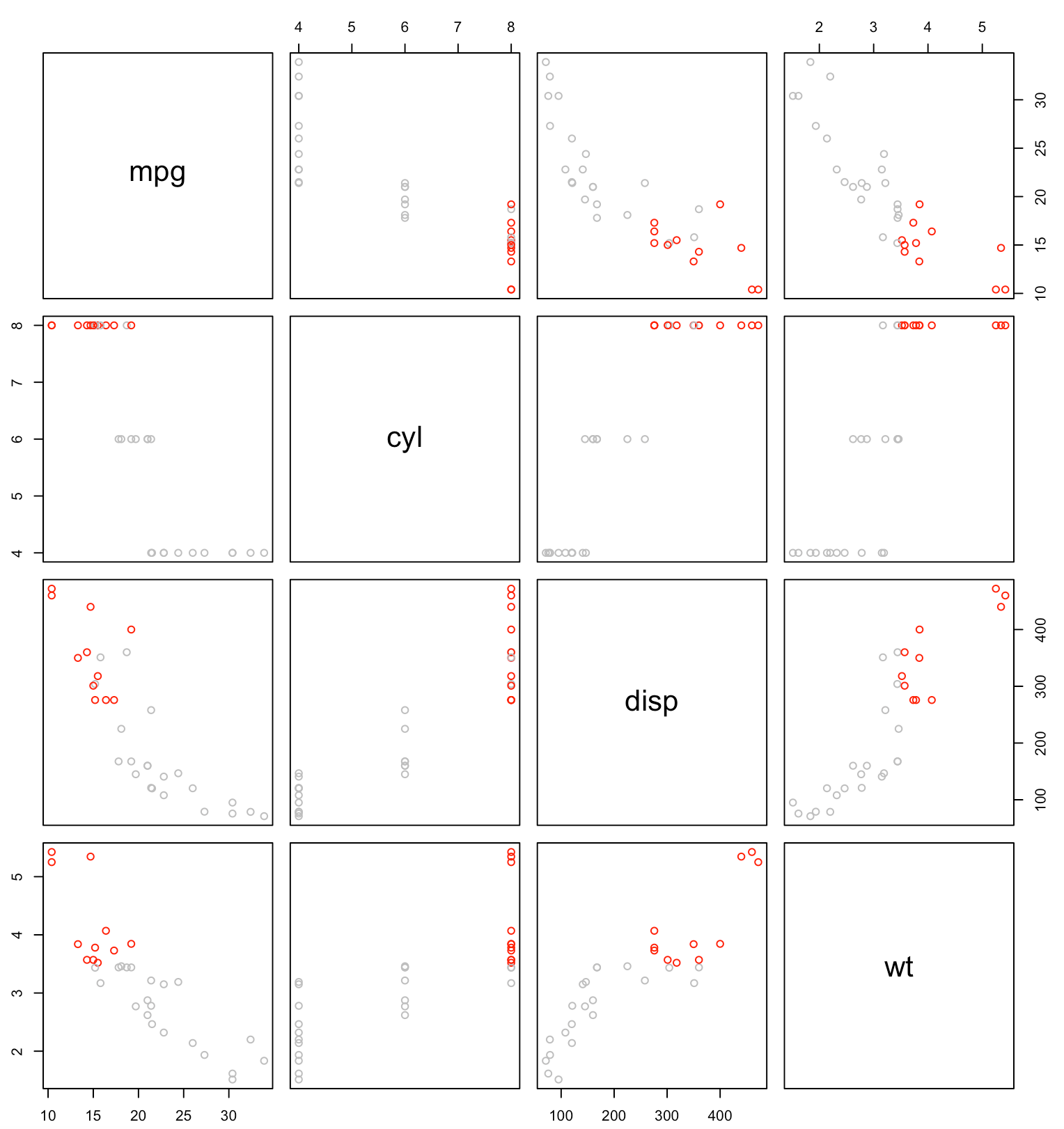
With a scatter plot matrix each variable is shown on the horizontal and vertical axis and we can see how pairs of variables relate to each other in their own 2D scatterplot, e.g. I can compare MPG to Horsepower, MPG to Weight, Horsepower VS Weight, etc.) and see how they relate.
Both allow me to brush and select a subset of the data and see it reflected across the dimensions. For example on the Parallel Coordinates example only 8 cylinder cars are selected (in red) showing that those tend to have lower MPG, more horsepower, more weight, lower acceleration, built across many years, but only in the USA. Similarly on the Scatterplot Matrix the 8 cylinder cars are selected (in red) and you can see those cars in all the other views.
 |
 |
Both of these techniques work when you have a small number of dimensions, or a dataset that you can reduce to a small number of dimensions.
R has these capabilities
in R you can get a list of the pre-installed
datasets with
data()
once you have some data
pairs gives you a scatterplot matrix, e.g. for the car dataset, pairs(~mpg+cyl+disp+wt,data=mtcars)
you can also use color to show subset of the
data e.g. isHeavy <- ifelse(mtcars$wt > 4, "red",
"grey")
and then pairs(~mpg+cyl+disp+wt,data=mtcars, col=isHeavy)
to show the heavier cars in red
 |
 |
you could also use a categorical value to set the colors, for
example coloring by the number of cylinders: colorBycyl =
as.numeric(mtcars$cyl) and then you could see that coloring
reflected across the matrix: pairs(~mpg+cyl+disp+wt,data=mtcars,
col=colorBycyl)
library(MASS) gives you access to a parallel
coordinate plot
 |
 |
Geospatial Visualization
last
revision 2/3/2022 - added in some more info on the history of
the Chicago L lines and their colors
2/1/2022 - added in an additional example of using colors in the
parallel coordinates and scatterplot matrices