Speech Conversion
Conversion to Clear Speech using Recurrent Neural Network
This my Master's Research Project. This Research is about converting casual or normal speech into Clear speech using a variation of a Recurrent Neural Network known as Bidirectional LSTMs. This is a novel research because it involves Speech conversion into a different kind of speech from the same speaker.
A two semester long project can be spanned literally into three stages: Getting the Right features, Training the Right model, Getting back the Right converted speech. The image below broadly shows these three stages.
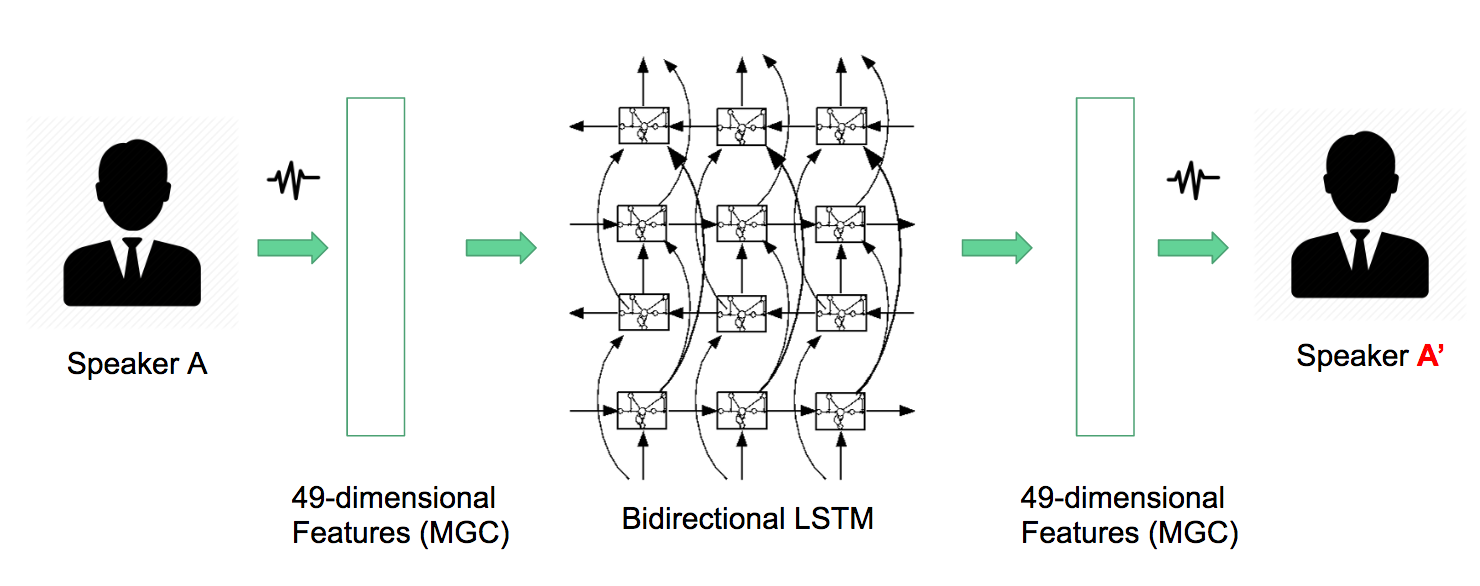
This architecture is influenced by Lifa Sun's research paper. Although the converted speech is from Speaker A -> Speaker A'.
Explaining the three stages:
1. Getting the Right Features: Firstly, align the phoenemes in the parallel corpora so that the sequences are of the same length. After alignment, we extract what is called Mel-Generalized Cepstral (MGCs) features using Audio Signal Processing techniques.

2. Training the Right model: We are using the lastest and greatest Deep Learning technique for Natural Language Processing, which is Bidirectional LSTMs. We are in the mid-stages of this training and optimization. Luckily, we have a good GPU access at the EVL. Infact we have a GPU-cluster for Visualization and other research.
3. Getting back the Right converted speech: After getting output from the Neural Network, we convert back the features into Sound files. The image below is one of the good resulting frames in the Converted speech. Green is from male voice, dashed red is from the desired female voice and solid red is from the converted voice.
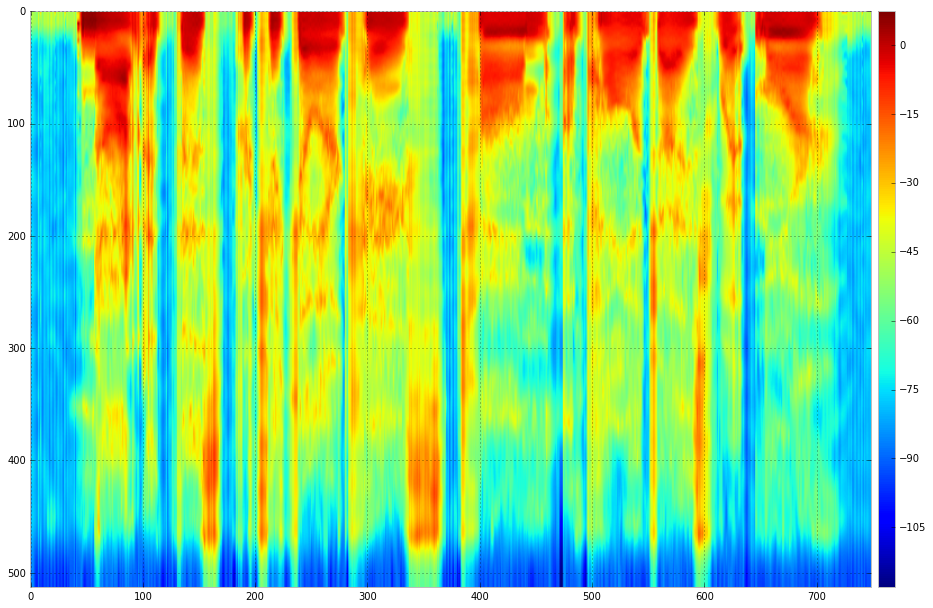
Desired female speech spectrum
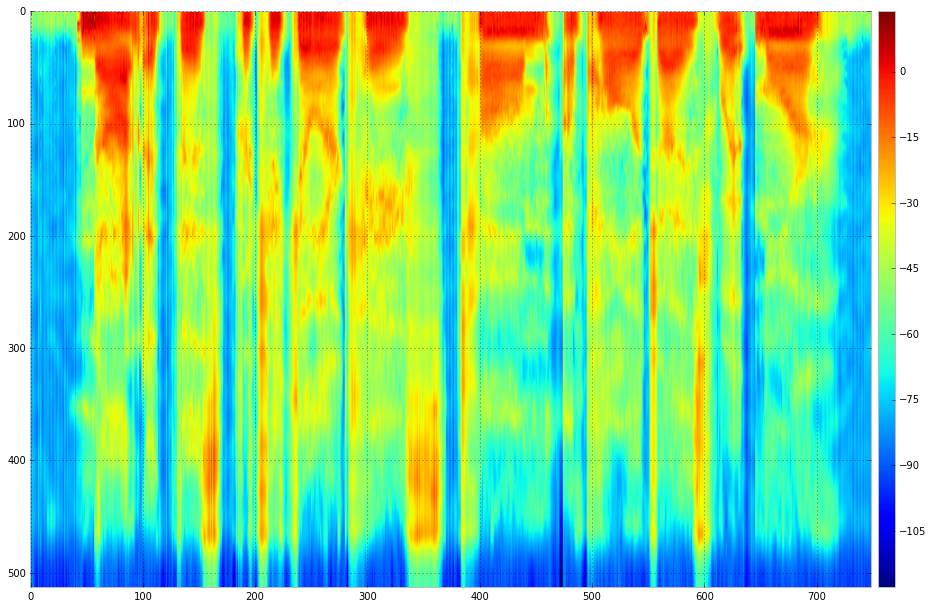
Speech spectrum obtained from the output of the bidirectional LSTM