|
CUDA Convolution- GPGPU Programming -Dec, 2008Sangyoon Lee (sjames @ evl.uic.edu)Electronic Visualization LaboratoryUniversity of Illinois at Chicago |
A given final exam is to explore CUDA optimization with Convoluiton filter application from nvidia's CUDA 2.0 SDK. There are three type of convolution filter in SDK. I mainly used convolutionTexture and convolutionSeparable application.
- Dataset (Images)
Images used in final is provided by Andy (see class website). I used 1kby1k, 2kby2k and 4kby4k image for performance testing. For some reason, 8kby8k image does not work well on my system.
- Development platform
Mac OSX 10.5, MacBook Pro 2.5GHz, Geforce 8600M GT 512MB, nvidia CUDA SDK 2.0
Intermediate and Final version of application is available to download and test. See more details in section 7 below.
Since there is well optimized application is available in SDK, I started to look at their code. First of all, original code uses random data instead of real images. Each data pixel in image represented as single float in these application. To make this application work with real image, I implemeted image loader and writer in RAW format. This code was slightly modified the module we used in project 2.
Each color component of pixel is composed of three values, RGB. To apply convolution filter on image, there are two ways. The first one is simply to map each component as single float and run convolution filter three times for each channel. The second apporach is to modify the original code to use uchar4 or int type as dataset so that we can compute separate channel value within CUDA kernel. I implemeted both ways in convolutionTexuture and convolutionSeparable but later on I only used the first method since it makes kernel code much simpler.
First thing I tried is top-down approach. I mean I took nvidia application and started to remove some of optimization techniques. Then, realized that it is not easy to make this all the way down to naive approach. So, restarted implementation from the most naive way and optimized it to close to the nvidia's application. Later section will explain these steps.
If you are not familiar with convolution filter, please take a look wikipedia entry, Gaussian blur or Convolution. Also, class lecture note (week4, convolution) is useful.
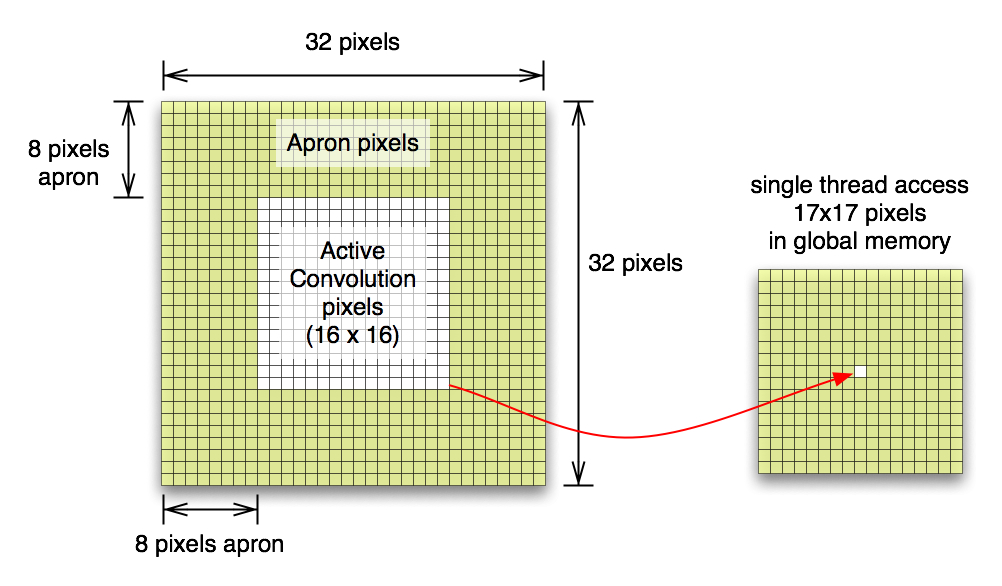
From the idea of convolutio filter itself, the most naive approach is to use global memory to send data to device and each thread accesses this to compute convolution kernel. Our convolution kernel size is radius 8 (total 17x17 multiplicaiton for single pixel value). In image border area, reference value will be set to 0 during computation. This naive approach includes many of conditional statements and this causes very slow execution.
There is no idle threads since total number of threads invoked is the same as total pixel numbers. CUDA kernel block size is 16x16. Below execution time is a mean value over 10 times execution. As you can see, it is extremely slow here.
Figure 1. Memory Access Pattern in Naive approach: each threads in block access 17x17 times global memory.
Below is CUDA kernel code.
__global__ void convolutionGPU(
...............................float *d_Result,
...............................float *d_Data,
...............................int dataW,
...............................int dataH )
{
....//////////////////////////////////////////////////////////////////////
....// most slowest way to compute convolution
....//////////////////////////////////////////////////////////////////////
....// global mem address for this thread
....const int gLoc = threadIdx.x +
.....................blockIdx.x * blockDim.x +
.....................threadIdx.y * dataW +
.....................blockIdx.y * blockDim.y * dataW;
....float sum = 0;
....float value = 0;
....for (int i = -KERNEL_RADIUS; i <= KERNEL_RADIUS; i++) // row wise
........for (int j = -KERNEL_RADIUS; j <= KERNEL_RADIUS; j++) // col wise
........{
............// check row first
............if (blockIdx.x == 0 && (threadIdx.x + i) < 0) // left apron
................value = 0;
............else if ( blockIdx.x == (gridDim.x - 1) &&
........................(threadIdx.x + i) > blockDim.x-1 ) // right apron
................value = 0;
............else
............{
................// check col next
................if (blockIdx.y == 0 && (threadIdx.y + j) < 0) // top apron
....................value = 0;
................else if ( blockIdx.y == (gridDim.y - 1) &&
............................(threadIdx.y + j) > blockDim.y-1 ) // bottom apron
....................value = 0;
................else // safe case
....................value = d_Data[gLoc + i + j * dataW];
............}
............sum += value * d_Kernel[KERNEL_RADIUS + i] * d_Kernel[KERNEL_RADIUS + j];
........}
........d_Result[gLoc] = sum;
}
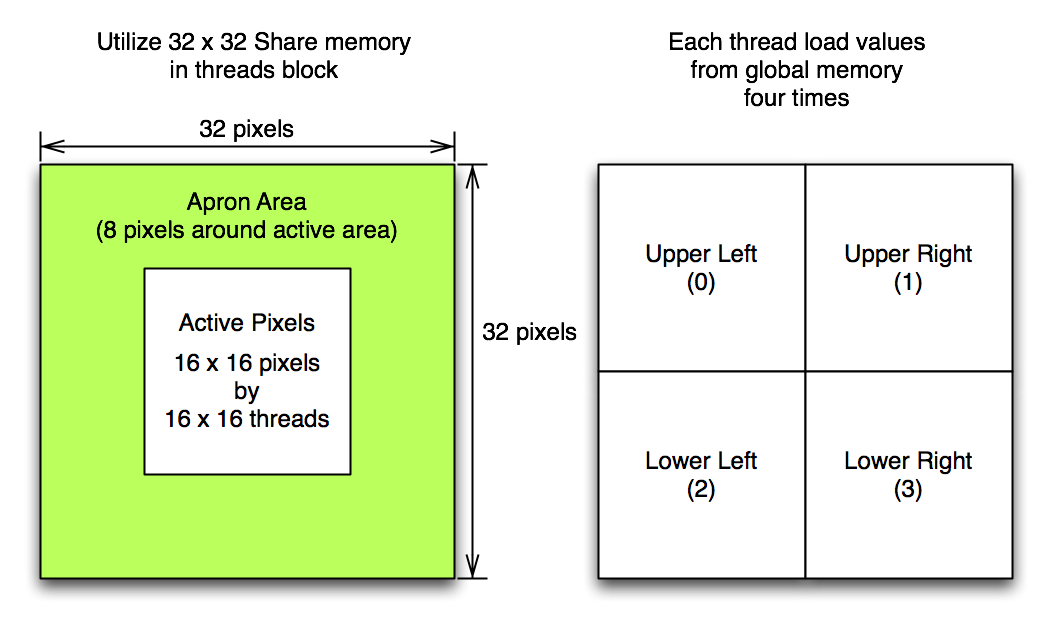
We all experienced the importance of shared memory throughout project 2. Now, it is time to incorporate with this feature from naive code. When I read nvidia convolution document, I thought that it is OK to invoke many of threads and each thread load data from global mem to shared mem. Then, let some of threads idle. Those are thread loaded apron pixels and do not compute convolution.
The first attempt was to keep active thread size as same as previous and increase block size for apron pixels. This did not work since convolution kernel radius is 8 and it make block size to 32 x 32 (1024). This is bigger than G80 hardware limit (512 threads max per block).
Therefore, I changes scheme as all threads are active and each thread loads four pixels and keep the block size 16x16. Shared Memory size used is 32x32 (this includes all necessary apron pixel values for 16x16 active pixels). Below shows quite a bit of performance improve. This is almost x2.8 speed up over naive approach (in 2048 resolution).
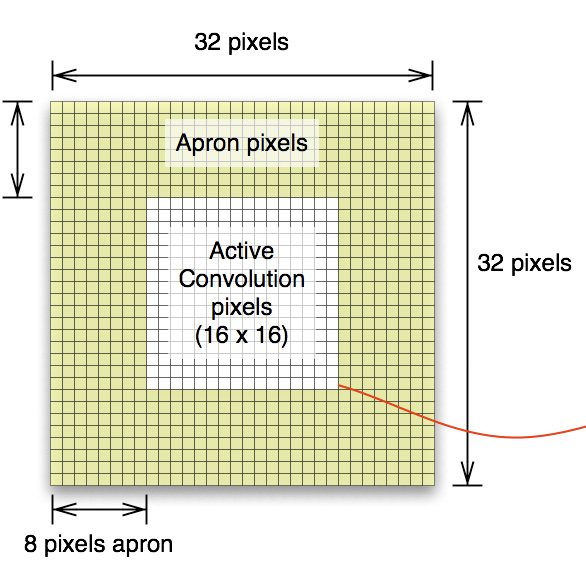
Figure 2. Shared Memory Model for naive approach: each threads in block load 4 values from global memory. Threfore, total shared memory size is 4 times bigger than active convolution pixels to include apron area (kernel radius 8 and block size 16x16. active pixels 256 float vs. shared memory size is 1024 float).
Below codes illustrate the convolution kernel.
__global__ void convolutionGPU(
................................float *d_Result,
................................float *d_Data,
................................int dataW,
................................int dataH
................................)
{
....// Data cache: threadIdx.x , threadIdx.y
....__shared__ float data[TILE_W + KERNEL_RADIUS * 2][TILE_W + KERNEL_RADIUS * 2];
....// global mem address of this thread
....const int gLoc = threadIdx.x +
........................IMUL(blockIdx.x, blockDim.x) +
........................IMUL(threadIdx.y, dataW) +
........................IMUL(blockIdx.y, blockDim.y) * dataW;
....// load cache (32x32 shared memory, 16x16 threads blocks)
....// each threads loads four values from global memory into shared mem
....// if in image area, get value in global mem, else 0
....int x, y; // image based coordinate
....// original image based coordinate
....const int x0 = threadIdx.x + IMUL(blockIdx.x, blockDim.x);
....const int y0 = threadIdx.y + IMUL(blockIdx.y, blockDim.y);
....// case1: upper left
....x = x0 - KERNEL_RADIUS;
....y = y0 - KERNEL_RADIUS;
....if ( x < 0 || y < 0 )
........data[threadIdx.x][threadIdx.y] = 0;
....else
........data[threadIdx.x][threadIdx.y] = d_Data[ gLoc - KERNEL_RADIUS - IMUL(dataW, KERNEL_RADIUS)];
....// case2: upper right
....x = x0 + KERNEL_RADIUS;
....y = y0 - KERNEL_RADIUS;
....if ( x > dataW-1 || y < 0 )
........data[threadIdx.x + blockDim.x][threadIdx.y] = 0;
....else
........data[threadIdx.x + blockDim.x][threadIdx.y] = d_Data[gLoc + KERNEL_RADIUS - IMUL(dataW, KERNEL_RADIUS)];
....// case3: lower left
....x = x0 - KERNEL_RADIUS;
....y = y0 + KERNEL_RADIUS;
....if (x < 0 || y > dataH-1)
........data[threadIdx.x][threadIdx.y + blockDim.y] = 0;
....else
........data[threadIdx.x][threadIdx.y + blockDim.y] = d_Data[gLoc - KERNEL_RADIUS + IMUL(dataW, KERNEL_RADIUS)];
....// case4: lower right
....x = x0 + KERNEL_RADIUS;
....y = y0 + KERNEL_RADIUS;
....if ( x > dataW-1 || y > dataH-1)
........data[threadIdx.x + blockDim.x][threadIdx.y + blockDim.y] = 0;
....else
........data[threadIdx.x + blockDim.x][threadIdx.y + blockDim.y] = d_Data[gLoc + KERNEL_RADIUS + IMUL(dataW, KERNEL_RADIUS)];
....__syncthreads();
....// convolution
....float sum = 0;
....x = KERNEL_RADIUS + threadIdx.x;
....y = KERNEL_RADIUS + threadIdx.y;
....for (int i = -KERNEL_RADIUS; i <= KERNEL_RADIUS; i++)
........for (int j = -KERNEL_RADIUS; j <= KERNEL_RADIUS; j++)
............sum += data[x + i][y + j] * d_Kernel[KERNEL_RADIUS + j] * d_Kernel[KERNEL_RADIUS + i];
....d_Result[gLoc] = sum;
}
One more optimization tested here. The use of faster integer multiplication instruction (above code already has this change), __mul24. After replacing all integer multiplication with __mul24, I got slight better performance.
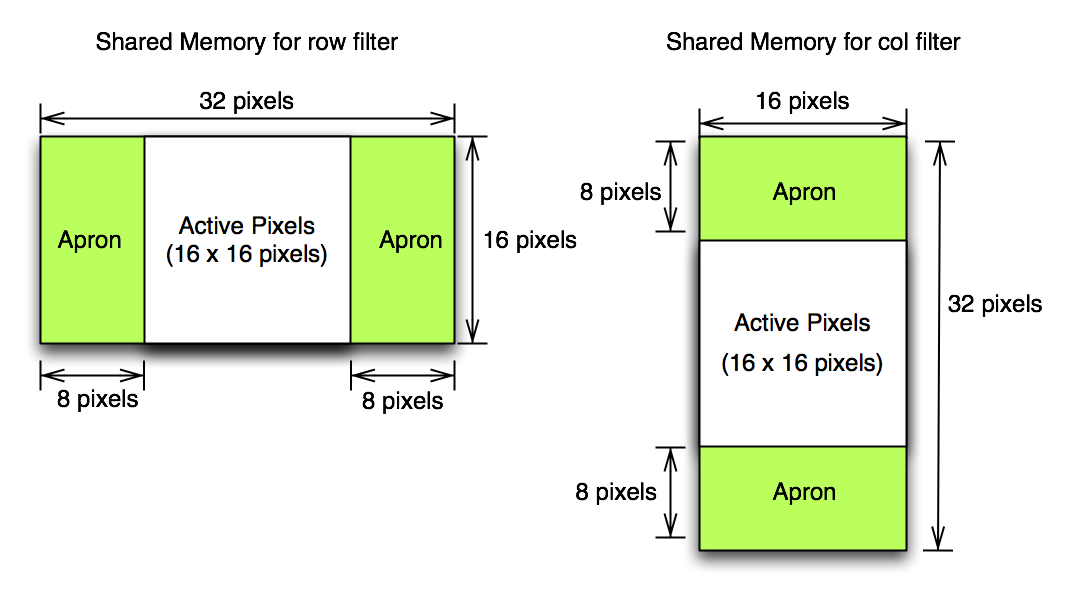
Here very important aspect of convolution filter is that it can be separated by row and column. This will reduce computation complexity from m*m to m+m. Basically we apply two separate convolution. The first one is row-wise and the second one is column-wise from the first result data (apply column convolution over row-wise filtered data). This also reduces some of conditional statement and total number of apron pixel data in each path since we do not need to consider vertical apron in row-convolution kernel and horizontal apron in column-convolution kernel.
This gives me a great improvement over the last shared memory optimized version. This is almost x6.2 speed-up from the last version (in resolution 2048). Code already includes __mul24 instruction.
Figure 3. Shared Memory for separate filter: this time only twice bigger memory is necessary for each filter
Unfortunately compiler directive for loopunroll (#pragma unroll 17) does not give any significat improvement. Below shows kernel code for separable convolution filter. Applicatin also modified to run twice of the kernel for row and col convolution.
////////////////////////////////////////////////////////////////////////////////
// Row convolution filter
////////////////////////////////////////////////////////////////////////////////
__global__ void convolutionRowGPU(
....................................float *d_Result,
....................................float *d_Data,
....................................int dataW,
....................................int dataH
..................................)
{
....// Data cache: threadIdx.x , threadIdx.y
....__shared__ float data[TILE_W + KERNEL_RADIUS * 2][TILE_H];
....// global mem address of this thread
....const int gLoc = threadIdx.x +
........................IMUL(blockIdx.x, blockDim.x) +
........................IMUL(threadIdx.y, dataW) +
........................IMUL(blockIdx.y, blockDim.y) * dataW;
....int x; // image based coordinate
....// original image based coordinate
....const int x0 = threadIdx.x + IMUL(blockIdx.x, blockDim.x);
.... // case1: left
....x = x0 - KERNEL_RADIUS;
....if ( x < 0 )
........data[threadIdx.x][threadIdx.y] = 0;
....else
........data[threadIdx.x][threadIdx.y] = d_Data[ gLoc - KERNEL_RADIUS];
.... // case2: right
....x = x0 + KERNEL_RADIUS;
....if ( x > dataW-1 )
........data[threadIdx.x + blockDim.x][threadIdx.y] = 0;
....else
........data[threadIdx.x + blockDim.x][threadIdx.y] = d_Data[gLoc + KERNEL_RADIUS];
.... __syncthreads();
....// convolution
....float sum = 0;
....x = KERNEL_RADIUS + threadIdx.x;
....
....for (int i = -KERNEL_RADIUS; i <= KERNEL_RADIUS; i++)
........sum += data[x + i][threadIdx.y] * d_Kernel[KERNEL_RADIUS + i];
.... d_Result[gLoc] = sum;
}
////////////////////////////////////////////////////////////////////////////////
// Column convolution filter
////////////////////////////////////////////////////////////////////////////////
__global__ void convolutionColGPU(
....................................float *d_Result,
....................................float *d_Data,
....................................int dataW,
....................................int dataH
.................................)
{
....// Data cache: threadIdx.x , threadIdx.y
....__shared__ float data[TILE_W][TILE_H + KERNEL_RADIUS * 2];
.... // global mem address of this thread
....const int gLoc = threadIdx.x +
........................IMUL(blockIdx.x, blockDim.x) +
........................IMUL(threadIdx.y, dataW) +
........................IMUL(blockIdx.y, blockDim.y) * dataW;
....int y; // image based coordinate
....// original image based coordinate
....const int y0 = threadIdx.y + IMUL(blockIdx.y, blockDim.y);
....// case1: upper
....y = y0 - KERNEL_RADIUS;
....if ( y < 0 )
........data[threadIdx.x][threadIdx.y] = 0;
....else
........data[threadIdx.x][threadIdx.y] = d_Data[ gLoc - IMUL(dataW, KERNEL_RADIUS)];
....// case2: lower
....y = y0 + KERNEL_RADIUS;
....if ( y > dataH-1 )
........data[threadIdx.x][threadIdx.y + blockDim.y] = 0;
....else
........data[threadIdx.x][threadIdx.y + blockDim.y] = d_Data[gLoc + IMUL(dataW, KERNEL_RADIUS)];
....__syncthreads();
....// convolution
....float sum = 0;
....y = KERNEL_RADIUS + threadIdx.y;
....for (int i = -KERNEL_RADIUS; i <= KERNEL_RADIUS; i++)
........sum += data[threadIdx.x][y + i] * d_Kernel[KERNEL_RADIUS + i];
....d_Result[gLoc] = sum;
}
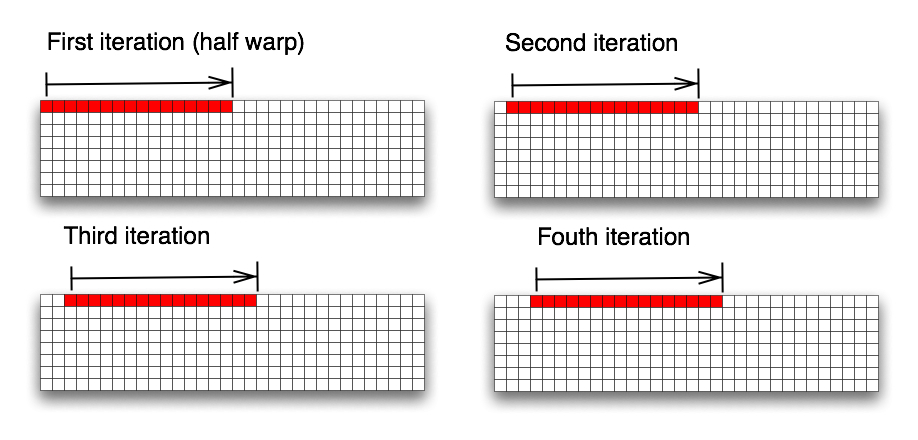
Until step 2, I used 2D array of shared memory to make indexing a bit simpler. Inside computation loop, there is possibility of bank conflict for warp since each thread access first column major memory at the same time. Now, let's re-arrange this shared memory to 1D array so that all threads access data consequently and optimize memory bus here. This only requires changes of indexing in kernel code. Below table shows performance after this re-arrange.
Figure 4. 1D Shared Memory Access Pattern for row filter: shows the first four iteration of convolution computataion. red area is indicating values accessed by half warp threads. Even we obtained fair amount speed up with this re-arrangement, memory access pattern is not aligned well enough to meet the requirement of half-warp alignment for optimal performance.
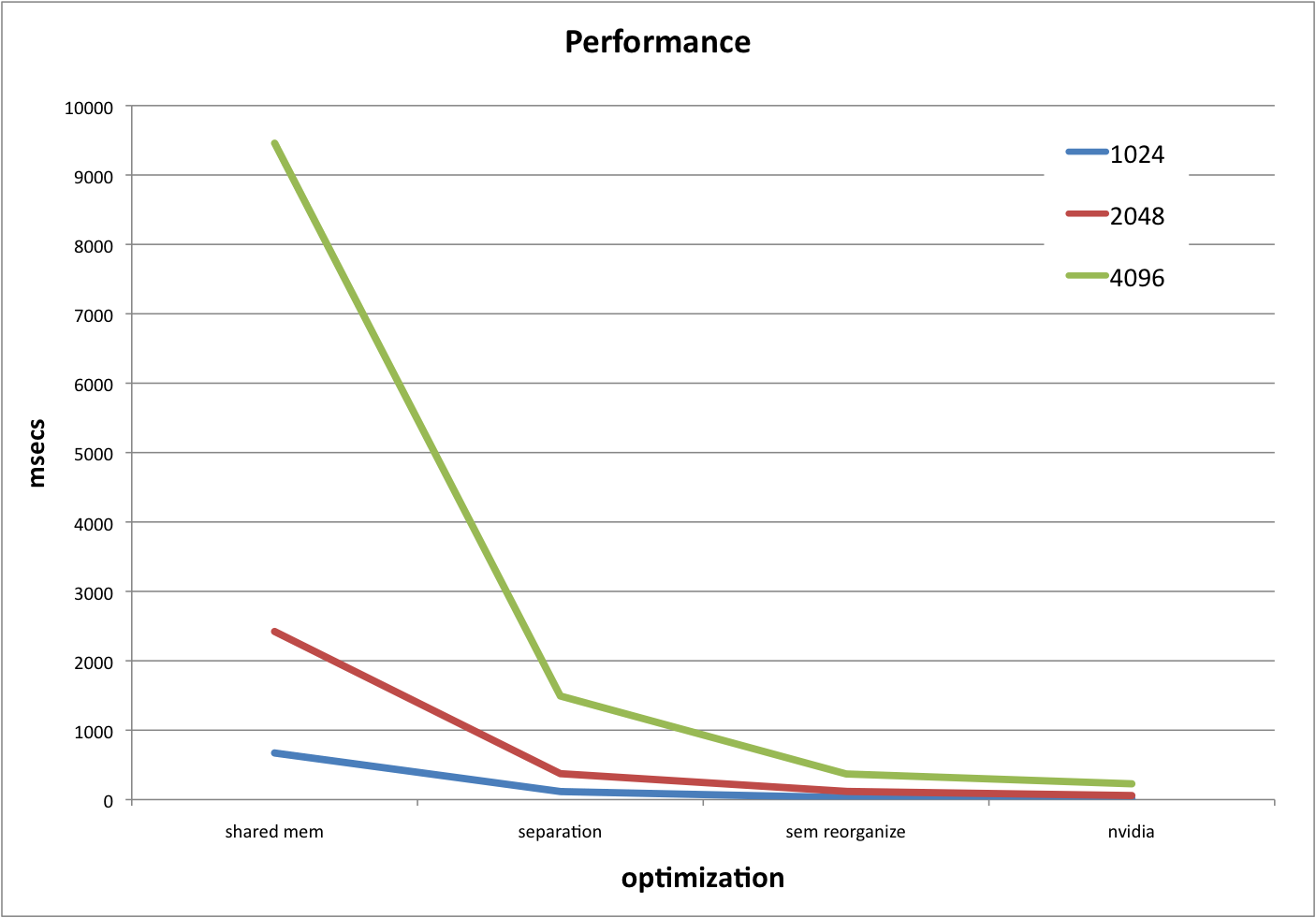
As you can see above table data, it achived about x3.2 speed-up over the first separable convoluiton implementation (in resolution 2048). Following shows kernel code for this optimization. From step 0 to this point, we made x57 speed-up overall (in resolution 2048).
////////////////////////////////////////////////////////////////////////////////
// Row convolution filter
////////////////////////////////////////////////////////////////////////////////
__global__ void convolutionRowGPU(
................................................float *d_Result,
................................................float *d_Data,
................................................int dataW,
................................................int dataH
.............................................)
{
....// Data cache: threadIdx.x , threadIdx.y
....__shared__ float data[ TILE_H * (TILE_W + KERNEL_RADIUS * 2) ];
....// global mem address of this thread
....const int gLoc = threadIdx.x +
............................IMUL(blockIdx.x, blockDim.x) +
............................IMUL(threadIdx.y, dataW) +
............................IMUL(blockIdx.y, blockDim.y) * dataW;
....int x; // image based coordinate
....// original image based coordinate
....const int x0 = threadIdx.x + IMUL(blockIdx.x, blockDim.x);
....const int shift = threadIdx.y * (TILE_W + KERNEL_RADIUS * 2);
....// case1: left
....x = x0 - KERNEL_RADIUS;
....if ( x < 0 )
........data[threadIdx.x + shift] = 0;
....else
........data[threadIdx.x + shift] = d_Data[ gLoc - KERNEL_RADIUS];
....// case2: right
....x = x0 + KERNEL_RADIUS;
....if ( x > dataW-1 )
........data[threadIdx.x + blockDim.x + shift] = 0;
....else
........data[threadIdx.x + blockDim.x + shift] = d_Data[gLoc + KERNEL_RADIUS];
....__syncthreads();
....// convolution
....float sum = 0;
....x = KERNEL_RADIUS + threadIdx.x;
....for (int i = -KERNEL_RADIUS; i <= KERNEL_RADIUS; i++)
........sum += data[x + i + shift] * d_Kernel[KERNEL_RADIUS + i];
....d_Result[gLoc] = sum;
}
////////////////////////////////////////////////////////////////////////////////
// Row convolution filter
////////////////////////////////////////////////////////////////////////////////
__global__ void convolutionColGPU(
....................................float *d_Result,
....................................float *d_Data,
....................................int dataW,
....................................int dataH
..................................)
{
....// Data cache: threadIdx.x , threadIdx.y
....__shared__ float data[TILE_W * (TILE_H + KERNEL_RADIUS * 2)];
....// global mem address of this thread
....const int gLoc = threadIdx.x +
........................IMUL(blockIdx.x, blockDim.x) +
........................IMUL(threadIdx.y, dataW) +
........................IMUL(blockIdx.y, blockDim.y) * dataW;
....int y; // image based coordinate
....// original image based coordinate
....const int y0 = threadIdx.y + IMUL(blockIdx.y, blockDim.y);
....const int shift = threadIdx.y * (TILE_W);
....// case1: upper
....y = y0 - KERNEL_RADIUS;
....if ( y < 0 )
........data[threadIdx.x + shift] = 0;
....else
........data[threadIdx.x + shift] = d_Data[ gLoc - IMUL(dataW, KERNEL_RADIUS)];
....// case2: lower
....y = y0 + KERNEL_RADIUS;
....const int shift1 = shift + IMUL(blockDim.y, TILE_W);
....if ( y > dataH-1 )
........data[threadIdx.x + shift1] = 0;
....else
........data[threadIdx.x + shift1] = d_Data[gLoc + IMUL(dataW, KERNEL_RADIUS)];
....__syncthreads();
....// convolution
....float sum = 0;
....for (int i = 0; i <= KERNEL_RADIUS*2; i++)
........sum += data[threadIdx.x + (threadIdx.y + i) * TILE_W] * d_Kernel[i];
....d_Result[gLoc] = sum;
}
In step 3, we made many of optimizations and improved performance greately. Now, there is a bit of further possible optimization to maximize memory bandwidth by change block organization as we see in nvidia's convolution document. Instead of changing code from step 3, I modified nvidia's original code to use image data to see the difference in performance. As I explained in the very beginning, there are two version of convolution app from nvidia. Following table shows those two application performance (modiifed version).
Compared to the result from step 3, convolutionSeparable optimization shows x2 speed-up (in resolution 2048). This application's kernel code is the same as the original one from nvidia. Only applicaiton side code is modified.
Below table shows a couple of experiments I ran at the beginning of top-down approach with this code (original nvidia convolutionSeparable app).
As we can see here, loop unrolling does not impact on performance that much but __mul24 intruction gives x1.3 speed-up.
Here is a brief performance chart from step 1 to step 4 (step 0 is excludes due to its huge number).
Here are three different version of convolution application. The first one is my own implemetation until step 3 and the other two applicaitons are the one I modified to use texture image instead of random data from nvidia application (see details in section 2 & 7).
Image Data: hubble.tar.gz (34MB. only include 1kby1k, 2kby2k, 4kby4k raw image from Andy's ditribution)
Need to copy these image file in directory name of hubble at the same level of each convolution application directory. (if you copied application in xxx/convolution directory, then image directory must be xxx/hubble )
Download application source & executable:
convolution.tar.gz (version of step 3)
convolutionTexture.tar.gz (version of step 4, texture)
convolutionSeparable.tar.gz (version of step 4, separable)
Execution
inside bin/darwin/release
./convolution [-i=image resolution] [-n=number of total run]
./convolutionTexture [-i=image resolution] [-n=number of total run]
./convolutionSeparable [-i=image resolution] [-n=number of total run]
default image resolution is 1024 and total run is 10 times.
Compile
in each application directory, type 'make'
[1] Nvidia CUDA Programming Guide 2.0, http://www.nvidia.com/object/cuda_develop.html
[2] Victor Podlozhnyuk, Image Convolution with CUDA, nvidia CUDA 2.0 SDK convolutionSpeparable document