
Improving Data Movement Performance for Sparse Data Patterns on the Blue Gene/Q Supercomputer
September 12th, 2014
Categories: Networking, Software, Supercomputing
Authors
Bui, H., Leigh, J., Jung, E., Vishwanath, V., Papka, M.About
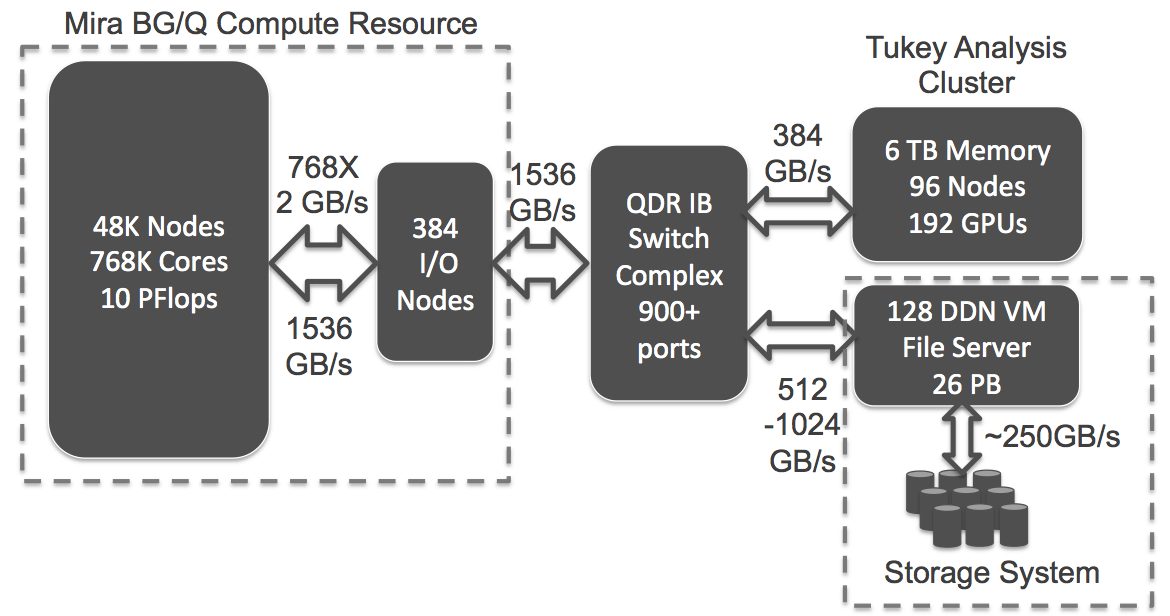
In-situ analysis has been proposed as a promising solution to glean faster insight and to reduce the amount of data written out to storage. A critical challenge here is that the reduced dataset needed to visualize a specific region of interest as the simulation is running is typically held on a subset of the nodes and needs to be written out to storage. Coupled multi-physics simulations also produce a sparse data pattern wherein data movement occurs among a subset of nodes. We evaluate the performance of these data patterns and propose several mechanisms for improving performance. Our mechanisms introduce intermediate nodes to implement multiple paths to transfer data on top of default routing algorithms and utilize topology-aware data aggregation to avoid shared bottleneck links. The efficacy of our solutions is evaluated through micro-benchmarks and application benchmarks on an IBM Blue Gene/Q system scaling up to 131,072 compute cores. The results show that our algorithms achieve up to a 2X improvement in achievable throughput compared to the default mechanisms.
Keywords: multiple paths, sparse data movement, topology-aware aggregation, data-intensive, BG/Q
Resources
Citation
Bui, H., Leigh, J., Jung, E., Vishwanath, V., Papka, M., Improving Data Movement Performance for Sparse Data Patterns on the Blue Gene/Q Supercomputer, Seventh International Workshop on Parallel Programming Models and Systems Software for High-End Computing (P2S2), 2014, Minneapolis, MN, September 12th, 2014.