
Improving Sparse Data Movement Performance Using Multiple Paths on the Blue Gene/Q Supercomputer
January 1st, 2016
Categories: Applications, High Performance Computing
Authors
Bui, H., Jung, E., Vishwanath, V., Johnson, A., Leigh, J., Papka, M.About
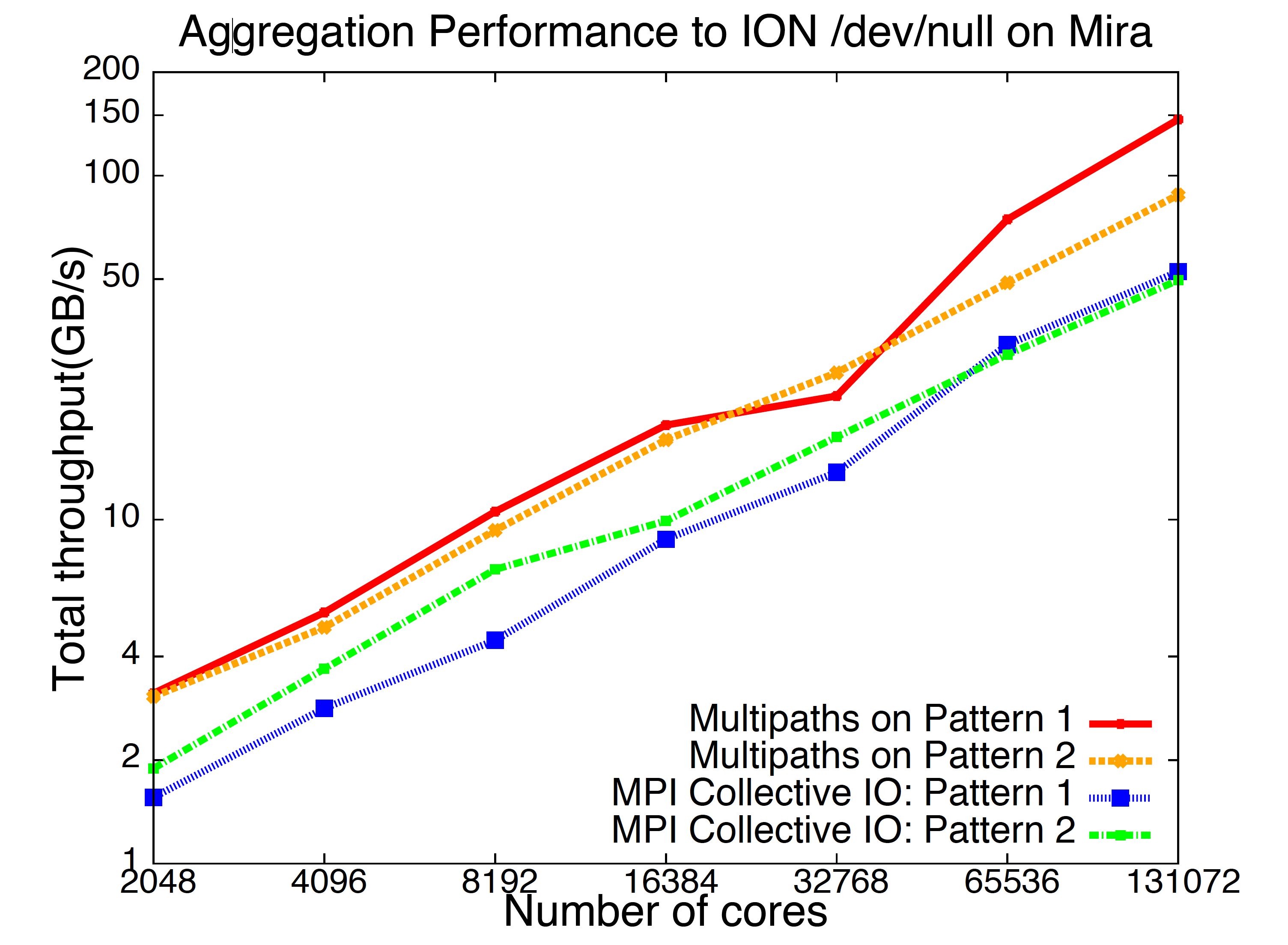
In situ analysis has been proposed as a promising solution to glean faster insights and reduce the amount of data to storage. A critical challenge here is that the reduced dataset is typically located on a subset of the nodes and needs to be written out to storage. Data coupling in multiphysics codes also exhibits a sparse data movement pattern wherein data movement occurs among a subset of nodes. We evaluate the performance of data movement for sparse data patterns on the IBM Blue Gene/Q supercomputing system “Mira” and identify performance bottlenecks. We propose a multipath data movement algorithm for sparse data patterns based on an adaptation of a maximum flow algorithm together with a breadth-first search that fully exploits all the underlying datapaths and I/O nodes to improve data movement. We demonstrate the efficacy of our solutions through a set of micro benchmarks and application benchmarks on Mira scaling up to 131,072 compute cores. The results show that our approach achieves up to 5X improvement in achievable throughput compared with the default mechanisms.
Keywords: multiple paths, sparse data movement, topology-aware aggregation, data-intensive, Blue Gene/Q
Resources
URL
Citation
Bui, H., Jung, E., Vishwanath, V., Johnson, A., Leigh, J., Papka, M., Improving Sparse Data Movement Performance Using Multiple Paths on the Blue Gene/Q Supercomputer, Parallel Computing, vol 51, pp. 3-16, January 1st, 2016. https://doi.org/10.1016/j.parco.2015.09.002