
Utilizing Image and Caption Information for Biomedical Document Classification
July 25th, 2021
Categories: Applications, Software, Visualization, Visual Analytics, Visual Informatics, Deep Learning, Data Science
Authors
Li, P., Zhang, G., Jiang, X., Trelles Trabucco, J., Raciti, D., Smith, C., Ringwald, M., Marai, G.E., Arighi, C., Shatkay, H.About
Motivation: Biomedical research findings are typically disseminated through publications. To simplify access to domain-specific knowledge while supporting the research community, several biomedical databases devote significant effort to manual curation of the literature - a labor intensive process. The first step toward biocuration requires identifying articles relevant to the specific area on which the database focuses. Thus, automatically identifying publications relevant to a specific topic within a large volume of publications is an important task toward expediting the biocuration process and, in turn, biomedical research. Current methods focus on textual contents, typically extracted from the title-and-abstract. Notably, images and captions are often used in publications to convey pivotal evidence about processes, experiments and results.
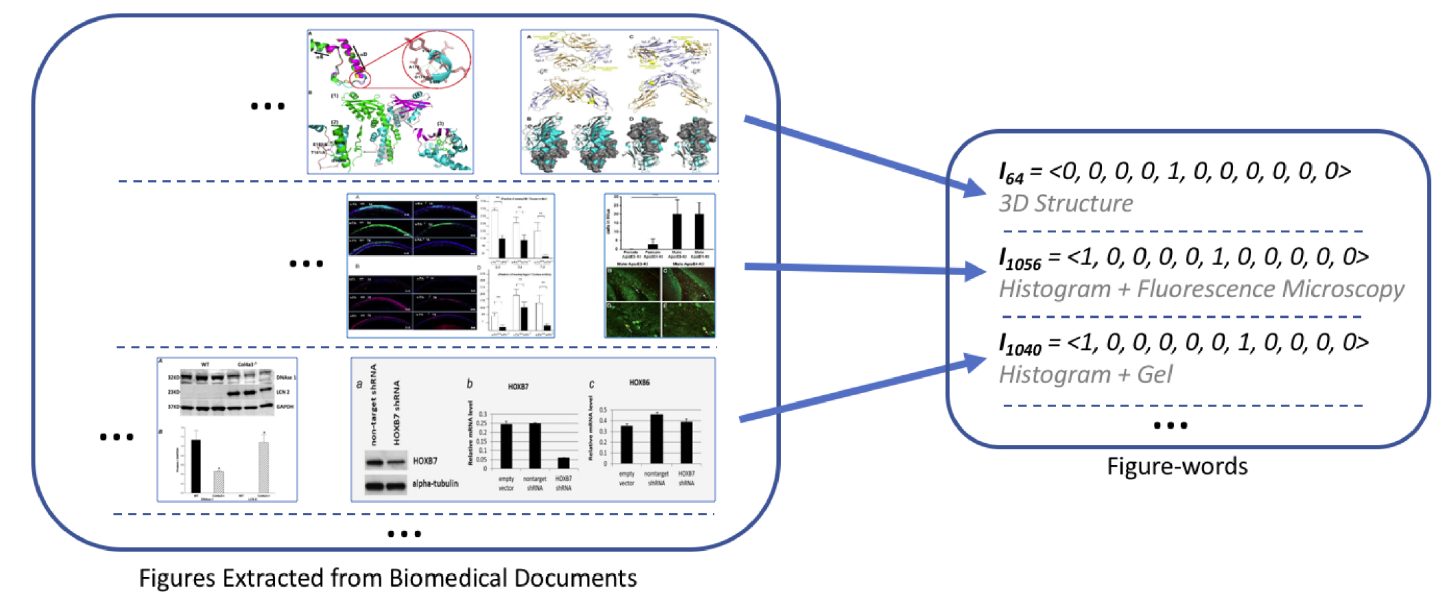
Results: We present a new document classification scheme, using both image and caption information, in addition to titles-and-abstracts. To use the image information, we introduce a new image representation, namely Figure-word, based on class labels of subfigures. We use word embeddings for representing captions and titles-and-abstracts. To utilize all three types of information, we introduce two information integration methods. The first combines Figure-words and textual features obtained from captions and titles-and-abstracts into a single larger vector for document representation; the second employs a meta-classification scheme. Our experiments and results demonstrate the usefulness of the newly proposed Figure-words for representing images. Moreover, the results showcase the value of Figure-words, captions and titles-and-abstracts in providing complementary information for document classification; these three sources of information when combined, lead to an overall improved classification performance.
Availability and implementation: Source code and the list of PMIDs of the publications in our datasets are available upon request.
https://doi.org/10.1093/bioinformatics/btab331
Resources
URL
Citation
Li, P., Zhang, G., Jiang, X., Trelles Trabucco, J., Raciti, D., Smith, C., Ringwald, M., Marai, G.E., Arighi, C., Shatkay, H., Utilizing Image and Caption Information for Biomedical Document Classification, Bioinformatics, ISMB/ECCB 2021, vol 37, Oxford University Press, pp. i468–i476, July 25th, 2021. https://academic.oup.com/bioinformatics/article/37/Supplement_1/i468/6319676