
Parameterized Algorithms for Non-uniform All-to-all
July 20th, 2025
Categories: Applications, Software, Supercomputing, Data Science, High Performance Computing
Authors
Fan, K., Domke, J., Ba, S., Kumar, S.About
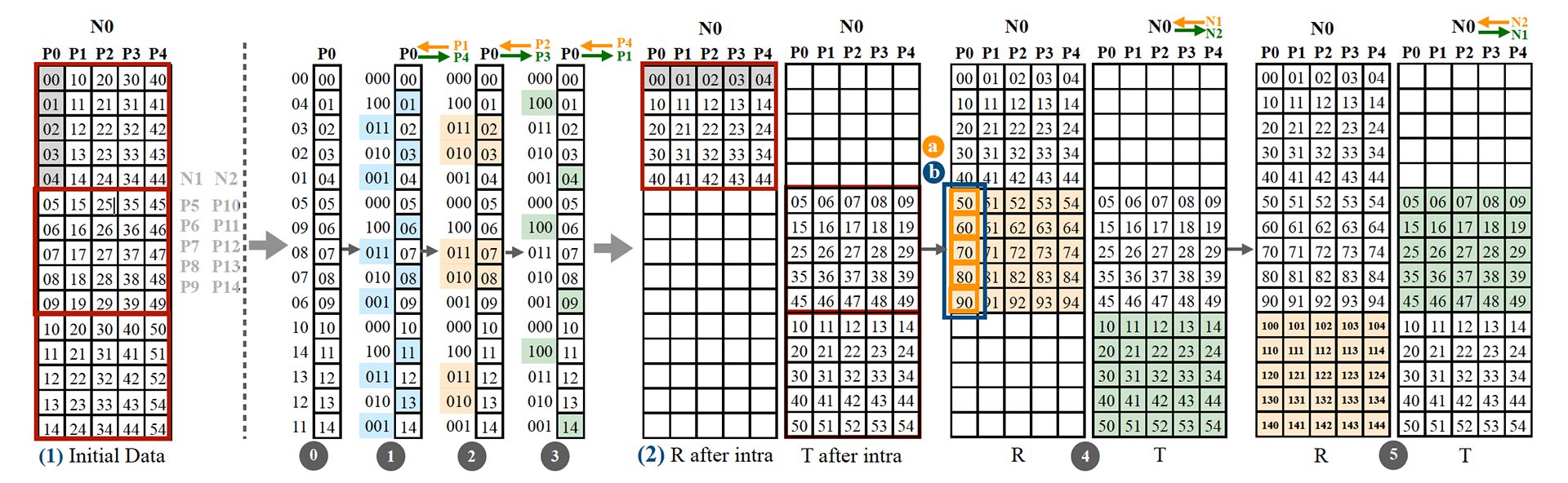
MPI_Alltoallv generalizes the uniform all-to-all communication (MPI_Alltoall) by enabling the exchange of data-blocks of varied sizes among processes. This function plays a crucial role in facilitating many computational tasks, such as FFT calculations and graph mining operations. Popular MPI libraries, such as MPICH and OpenMPI, implement MPI_Alltoall using a combination of linear and logarithmic algorithms. However, MPI_Alltoallv typically relies only on variations of linear algorithms, missing the benefits of logarithmic approaches. Furthermore, current algorithms also overlook the intricacies of modern HPC system architectures, such as the significant performance gap between intra-node (local) and inter-node (global) communication. To address these problems, this paper presents two novel algorithms: Parameterized Logarithmic non-uniform All-to-all (ParLogNa) and Parameterized Linear nonuniform All-to-all (ParLinNa). ParLogNa is a tunable logarithmic time algorithm for non-uniform all-to-all, and ParLinNa is a hierarchical and tunable near-linear-time algorithm for non-uniform all-to-all. These algorithms efficiently address the trade-off between bandwidth maximization and latency minimization that existing implementations struggle to optimize. We show a performance improvement over the state-of-the-art implementations by factors of 42x and 138x on Polaris and Fugaku, respectively.
https://doi.org/10.1145/3731545.3731590
Resources
URL
Citation
Fan, K., Domke, J., Ba, S., Kumar, S., Parameterized Algorithms for Non-uniform All-to-all, In The 34th International Symposium on High-Performance Parallel and Distributed Computing (HPDC ’25), Notre Dame, IN, ACM, New York, NY, July 20th, 2025. https://doi.org/10.1145/3731545.3731590