
From Prompts to Priorities: Pairwise Learning-to-Rank Scheduling for Low-Latency LLM Serving (poster)
May 8th, 2025
Categories: Applications, Supercomputing, Data Science, Artificial Intelligence, High Performance Computing
Authors
Tao, Y., Zhang, Y., Dearing, M. T., Wang, X., Lan, Z.About
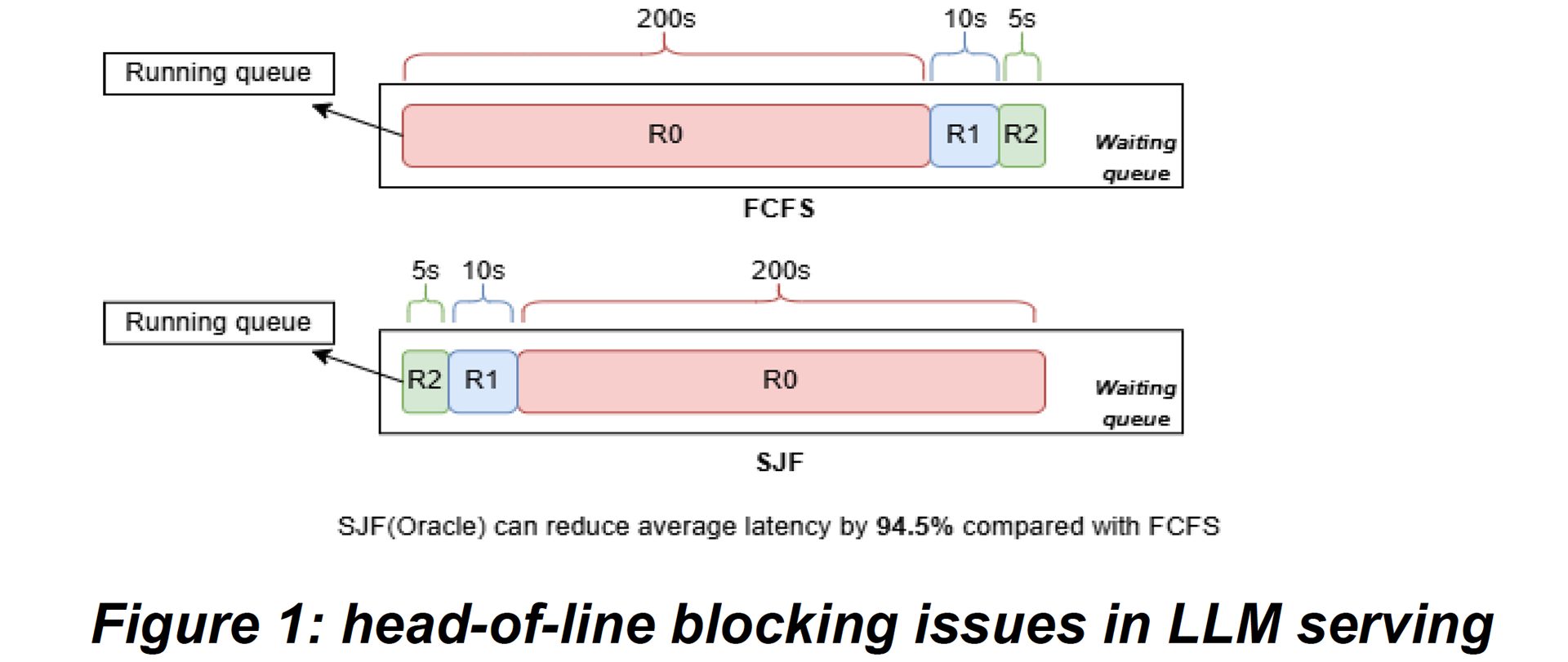
Large language model (LLM) requests vary widely: a short factual query may produce only a few dozen tokens, while multi-step reasoning or proof generation can run to tens of thousands. Because generation is autoregressive, inference time grows proportionally with output length. Current serving stacks such as vLLM and Orca schedule requests using a simple first-come-first-serve (FCFS) policy. While fair, FCFS suffers from a well-known issue in LLM serving called head-of-line blocking, where a single long request delays all shorter ones behind it - leading to inflated tail latency and wasted throughput. A classical remedy is the Shortest-Job-First (SJF) policy, which improves efficiency by serving shorter jobs first. However, SJF requires knowledge of job length in advance - information that is unavailable in LLMs until generation completes, due to their autoregressive nature.
We introduce a prompt-sensitive LLM task scheduler based on pairwise learning method from learning-to-rank utilizing Margin Ranking Loss and show that our method significantly improves scheduling performance with minimal overhead.
Resources
URL
Citation
Tao, Y., Zhang, Y., Dearing, M. T., Wang, X., Lan, Z., From Prompts to Priorities: Pairwise Learning-to-Rank Scheduling for Low-Latency LLM Serving (poster), The 12th Greater Chicago Area Systems Research Workshop (GCASR), Chicago, IL, May 8th, 2025. https://gcasr.org/2025/posters