
Augmenting Small Data to Classify Contextualized Dialogue Acts for Exploratory Visualization
May 11th, 2020
Categories: Applications, Software, Visualization, Natural Language Processing, Deep Learning, Human Computer Interaction (HCI), Machine Learning, Data Science, Artificial Intelligence
Authors
Kumar, A., Di Eugenio, B., Aurisano, J., Johnson, A.About
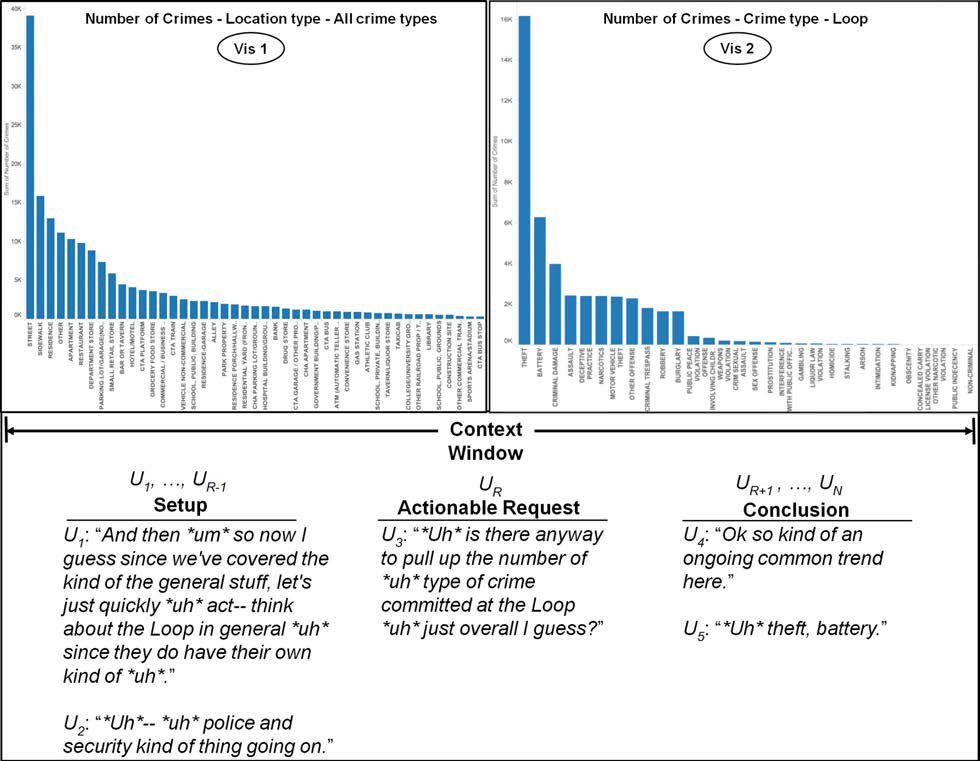
Our goal is to develop an intelligent assistant to support users explore data via visualizations. We have collected a new corpus of conversations, CHICAGO-CRIME-VIS, geared towards supporting data visualization exploration, and we have annotated it for a variety of features, including contextualized dialogue acts. In this paper, we describe our strategies and their evaluation for dialogue act classification. We highlight how thinking aloud affects interpretation of dialogue acts in our setting and how to best capture that information. A key component of our strategy is data augmentation as applied to the training data, since our corpus is inherently small. We ran experiments with the Balanced Bagging Classifier (BAGC), Condiontal Random Field (CRF), and several Long Short Term Memory (LSTM) networks, and found that all of them improved compared to the baseline (e.g., without the data augmentation pipeline). CRF outperformed the other classification algorithms, with the LSTM networks showing modest improvement, even after obtaining a performance boost from domain-trained word embeddings. This result is of note because training a CRF is far less resource-intensive than training deep learning models, hence given a similar if not better performance, traditional methods may still be preferable in order to lower resource consumption.
Keywords: Dialogue, Corpus, Statistical and Machine Learning Methods
Resources
URL
Citation
Kumar, A., Di Eugenio, B., Aurisano, J., Johnson, A., Augmenting Small Data to Classify Contextualized Dialogue Acts for Exploratory Visualization, In the Proceedings of The 12th Language Resources and Evaluation Conference, Marseille, France, European Language Resources Association, pp. 590-599, May 11th, 2020. https://www.aclweb.org/anthology/2020.lrec-1.74