
A Distributed Graph Approach for Pre-processing Linked RDF Data Using Supercomputers
May 18th, 2017
Categories: Data Science, High Performance Computing
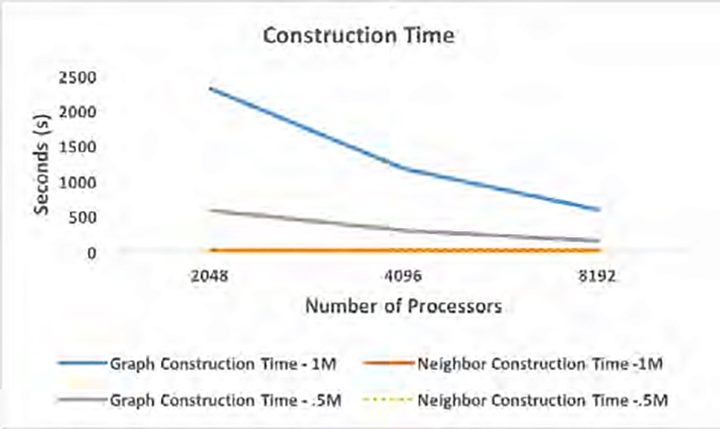
Graph construction and neighbor times over 1M, .5M triple dataset.
Authors
Lewis, M., Thiruvathakal, G., Vishwanath, V., Papka, M., Johnson, A.About
Efficient RDF, graph-based queries are becoming more pertinent based on the increased interest in data analytics and its intersection with large, unstructured but connected data. Many commercial systems have adopted distributed RDF graph systems in order to handle increasing dataset sizes and complex queries. This paper introduces a distribute graph approach to pre-processing linked data. Instead of traversing the memory graph, our system indexes pre-processed join elements that are organized in a graph structure. We analyze the Dbpedia data-set (derived from the Wikipedia cor-pus) and compare our access method to the graph traversal access approach which we also devise. Results show from our experiments that the distributed, pre-processed graph approach to accessing linked data is faster than the traversal approach over a specific range of linked queries.
CCS CONCEPTS: Computing methodologies, Distributed algorithms
KEYWORDS: RDF, High Performance Computing; Distributed Algorithms
Resources
URL
Citation
Lewis, M., Thiruvathakal, G., Vishwanath, V., Papka, M., Johnson, A., A Distributed Graph Approach for Pre-processing Linked RDF Data Using Supercomputers, In the Proceedings of Semantic Big Data 2017, Raleigh, SC, May 18th, 2017. https://doi.org/10.1145/3066911.3066913