
Linking scientific instruments and computation: Patterns, technologies, and experiences
October 14th, 2022
Categories: Applications, Software, Deep Learning, Machine Learning, Data Science, Artificial Intelligence, High Performance Computing
Authors
Vescovi, R., Chard, R., Saint, N.D., Blaiszik, B., Pruyne, J., Bicer, T., Lavens, A., Liu, Z., Papka, M.E., Narayanan, S., Schwarz, N., Chard, K., Foster, I.T.About
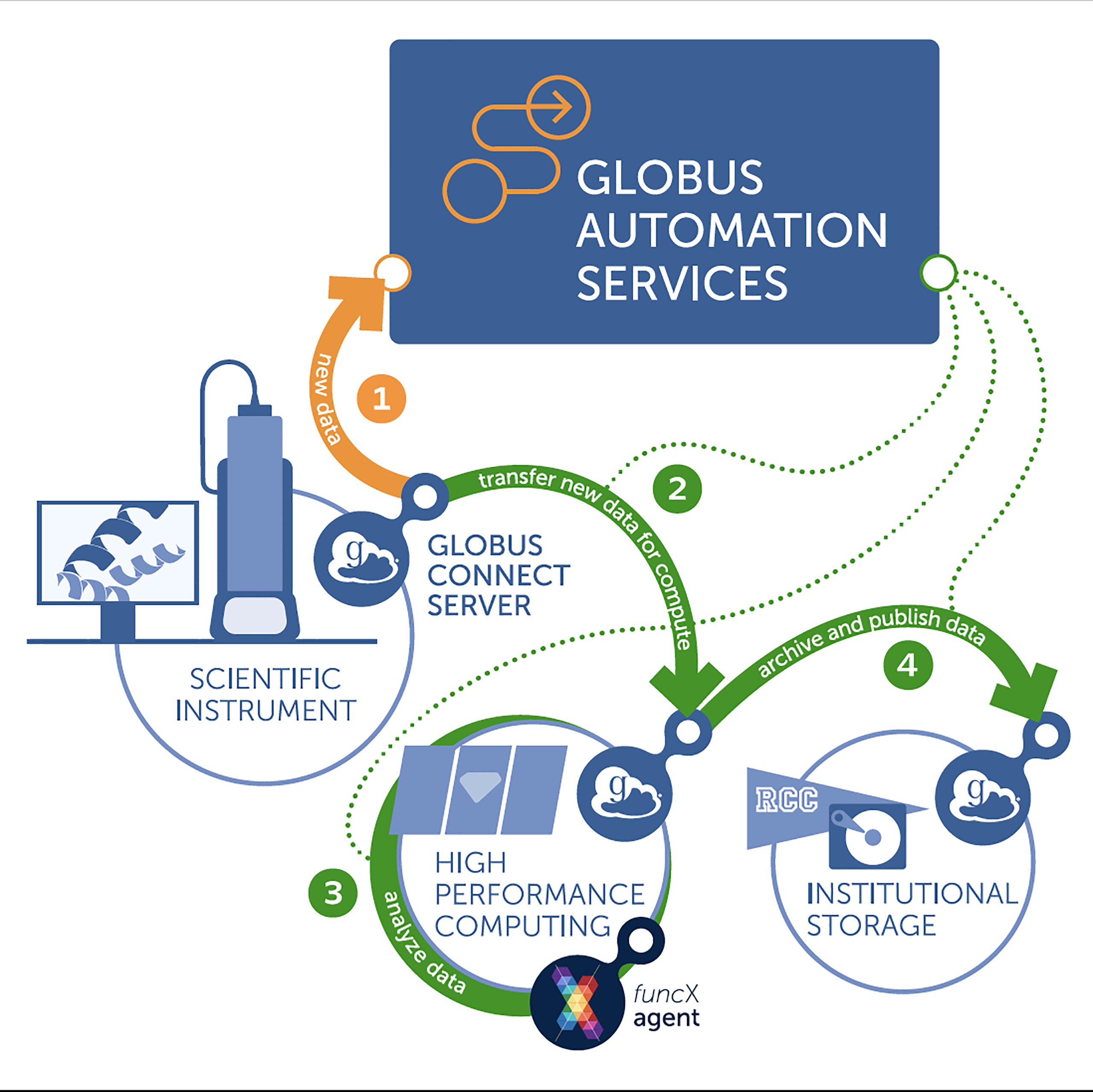
Powerful detectors at modern experimental facilities routinely collect data at multiple GB/s. Online analysis methods are needed to enable the collection of only interesting subsets of such massive data streams, such as by explicitly discarding some data elements or by directing instruments to relevant areas of experimental space. Thus, methods are required for configuring and running distributed computing pipelines-what we call flows-that link instruments, computers (e.g., for analysis, simulation, artificial intelligence [AI] model
training), edge computing (e.g., for analysis), data stores, metadata catalogs, and high-speed networks. We review common patterns associated with such flows and describe methods for instantiating these patterns.
We present experiences with the application of these methods to the processing of data from five different scientific instruments, each of which engages powerful computers for data inversion, model training, or other purposes. We also discuss implications of such methods for operators and users of scientific facilities.
https://www.cell.com/patterns/fulltext/S2666-3899(22)00231-8
Resources
URL
Citation
Vescovi, R., Chard, R., Saint, N.D., Blaiszik, B., Pruyne, J., Bicer, T., Lavens, A., Liu, Z., Papka, M.E., Narayanan, S., Schwarz, N., Chard, K., Foster, I.T., Linking scientific instruments and computation: Patterns, technologies, and experiences, Patterns 3, 100606, October 14th, 2022. https://doi.org/10.1016/j.patter.2022.100606