
DRAS: Deep Reinforcement Learning for Cluster Scheduling in High Performance Computing
December 1st, 2022
Categories: Applications, Software, User Groups, Deep Learning, Machine Learning, Data Science, Artificial Intelligence, High Performance Computing
Authors
Fan, Y., Li, B., Favorite, D., Singh, N., Childers, T., Rich, P., Allcock, W., Papka, M.E, Lan, Z.About
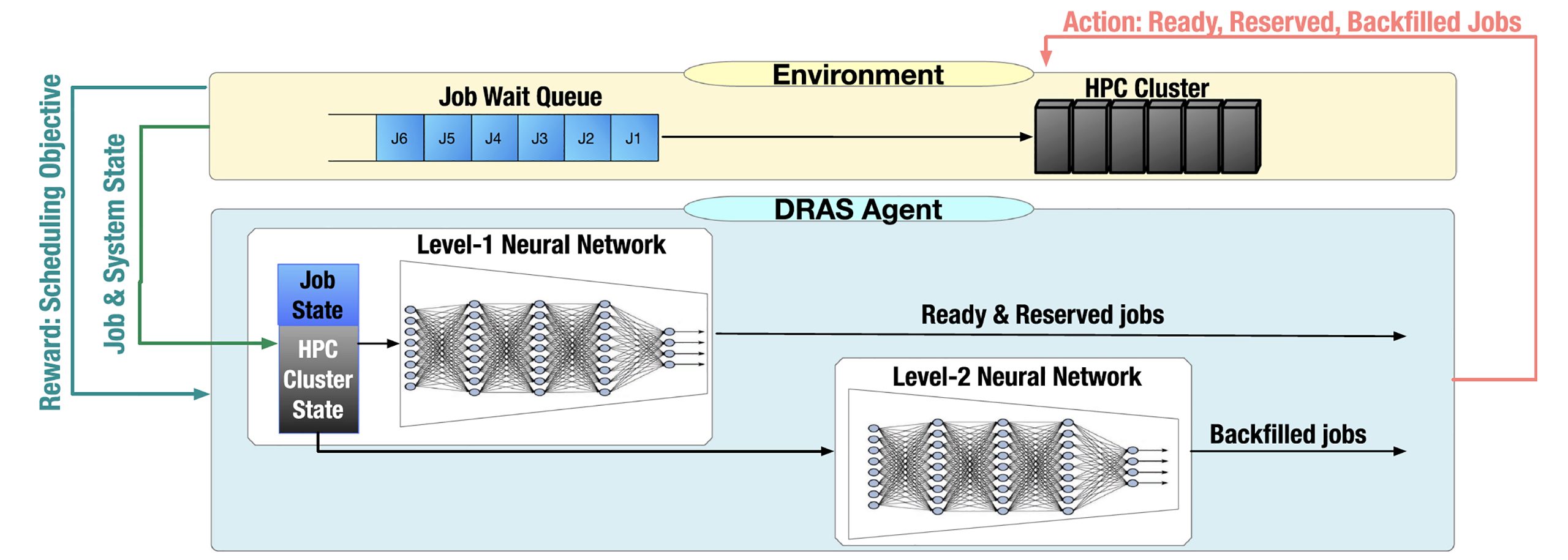
Cluster schedulers are crucial in high-performance computing (HPC). They determine when and which user jobs should be allocated to available system resources. Existing cluster scheduling heuristics are developed by human experts based on their experience with specific HPC systems and workloads. However, the increasing complexity of computing systems and the highly dynamic nature of application workloads have placed tremendous burden on manually designed and tuned scheduling heuristics. More aggressive optimization and automation are needed for cluster scheduling in HPC. In this work, we present an automated HPC scheduling agent named DRAS (Deep Reinforcement Agent for Scheduling) by leveraging deep reinforcement learning. DRAS is built on a hierarchical neural network incorporating special HPC scheduling features such as resource reservation and backfilling. An efficient training strategy is presented to enable DRAS to rapidly learn the target environment. Once being provided a specific scheduling objective given by the system manager, DRAS automatically learns to improve its policy through interaction with the scheduling environment and dynamically adjusts its policy as workload changes. We implement DRAS into an HPC scheduling platform called CQGym. CQGym provides a common platform allowing users to flexibly evaluate DRAS and other scheduling methods such as heuristic and optimization methods. The experiments using CQGym with different production workloads demonstrate that DRAS outperforms the existing heuristic and optimization approaches by up to 50%.
Index Terms - High-performance computing, cluster scheduling, deep reinforcement learning, job starvation, backfilling, resource reservation, OpenAI Gym
https://ieeexplore.ieee.org/abstract/document/9894371
Resources
URL
Citation
Fan, Y., Li, B., Favorite, D., Singh, N., Childers, T., Rich, P., Allcock, W., Papka, M.E, Lan, Z., DRAS: Deep Reinforcement Learning for Cluster Scheduling in High Performance Computing, IEEE Transactions on Parallel and Distributed Systems, vol 3, no 12, pp. 4903-4917, December 1st, 2022. https://doi.org/10.1109/TPDS.2022.3205325